
Grand Rapids Tech Lunch – Monday, September 8th
posted on 09/02/08 at 04:30:06 pm by Joel Ross
The fourth Grand Rapids TechLunch is coming up quickly, and I'm excited about our guest this time around. We're going to have Bill Kleven, who is a partner at DaVinci Capital, a local firm who's goal is to help businesses develop business strategies and secure financing to fund their business. He's going to be talking about the process that you'd go through to bring your idea to fruition.
It should be a good discussion, so head over to the GRTechLunch site and RSVP!
Categories: General
Entities and Repositories Discussion
posted on 08/28/08 at 06:13:35 pm by Joel Ross
Earlier today, there was a great discussion in an IRC channel about entities and whether they should have behaviors or not, and that eventually moved onto Repositories. It's a good discussion and after it was over, several of us felt it would be a good reference for later. Since I have a log of the conversation, I figured I'd repost it for future reference. Hopefully, you'll find it a good read as well.
For a bit of reference, this conversation took place in ##twittertribe on irc.freenode.net (yes, a double #). The main players are (in order of appearance) Michael Eaton (mjeaton), Eric Ridgeway (Ang3lFir3), Nate Kohari (nkohari), Matt Davis (mattsonlyattack), James Avery (averyj), Michael Letterle (TheProkrammer), me (RossCode), James Bender (JamesBender), Jay Wren (evarlast), and Nick Quaranto (qrush).
mjeaton: Ok. Entities - behaviors: yes or no?
Ang3lFir3: mjeaton: yes?
mjeaton: Ang3lFir3: serious question. what do you think?
nkohari: mjeaton: if you mean behaviors as in business logic, yes
Ang3lFir3: mjeaton: i've heard yes.. and I think its reasonable.... but i also think it could get out of hand
mjeaton: Ok. Customer class. Does it have a .Save()?
mattsonlyattack: activerecord--
Ang3lFir3: i see visions of Entities with 10 properties and 15 "Actions"
averyj: mjeaton: I would say yes
TheProkrammer: mjeaton: Ideally, no.
mjeaton: I LOVE IRC!
TheProkrammer: awesome. :)
Ang3lFir3: mjeaton: it has a Save if you are using active record
averyj: but if you want to be all IOC you could have the Customer class take an ICustomerRepository
mjeaton: you guys rock. guaranteed that any question I ask will result in a 50/50 split
averyj: and it uses that to save
TheProkrammer: Customers.Save(customer)
RossCode: mjeaton: I can see both ways, but for the most part, yes
nkohari: averyj: false
averyj: lol
nkohari: you want the ICustomerRepository to take a Customer, not the other way around
mattsonlyattack: the Customer class wouldn't take a repository
averyj: false
averyj: lol
mattsonlyattack: SRP bitches
nkohari: that's too activerecordy
JamesBender: Didn't we have this discussion already?
averyj: dont build an aenemic domain model for PIs sake
mjeaton: how many of you think PI is important?
nkohari: it's a nice-to-have
nkohari: it helps during development
RossCode: mjeaton: I don't, really
nkohari: but i don't buy the "oh i might switch dbms's" argument
mjeaton: nkohari: how does it help?
Ang3lFir3: PI is pretty.... but i would decide based on project scale
JamesBender: It makes some things easier
evarlast: averyj: the customer class wouldn't take an ICustomerRepository.
evarlast: Customer should have no deps other than its object relations.
nkohari: mjeaton: you can design against your domain model without worrying about where the entities are stored
nkohari: and you can create an in-memory backing store for testing
Ang3lFir3: scale and complexity of the domain... simple domain then i prolly don't need PI ... and go straight to AR
mjeaton: nkohari: /devils_advocate: explain domain model
nkohari: so you don't need to have a database during testing
evarlast: Repositories know about entities, but Entities need not and shouldn't know about their repositories. NH FTW, Entity Framework FTL
Ang3lFir3: evarlast++
nkohari: the term "domain model" sucks, but to me it means the entities that represent your business... ie. customer, order, invoice
RossCode: even with activerecord, you don't necessarily have to have a database to test
Ang3lFir3: nkohari: true
mjeaton: Ok. So UI talks to controller. Controller talks to ??
nkohari: repository
mjeaton: UI=View
nkohari: ICustomerRepository, for example
Ang3lFir3: mjeaton: controller uses repo and sends data to View (UI)
mjeaton: Controller talks to repository and returns instances/collections of Entities?
nkohari: yes
mattsonlyattack: or an application service
RossCode: nkohari: do you have one repository or multiple repositories?
mjeaton: mattsonlyattack: explain.
Ang3lFir3: technically the returned instances don't HAVE to be entities
nkohari: RossCode: lately i've been using one
evarlast: the nice thing about repo model is when you scale you can scale out and instead of talking direct to DB you can make your Repo talk to a web service or maybe something simple like ASP Dynamic Data and your entities and repository interfaces dont' change.
nkohari: but you can only get away with that in some cases
RossCode: nkohari: how do you handle custom queries? Pass in ICriteria?
Ang3lFir3: isn't the multiple repo thing about when you get into Aggregate roots etc?
mattsonlyattack: for behaviors that don't directly map to a single entity some times services are used to control the collaboration, and they'll use respositories as well
nkohari: yeah, in the past i have, but lately i've moved to linq for nh
nkohari: so it's all Expression<Func<T, bool>>s
Ang3lFir3: linq for nh FTW
RossCode: nkohari: but then aren't your queries and how you query data in your controllers now?
nkohari: "expressionfunktybools"
nkohari: RossCode: touche ;)
nkohari: chadmyers was just talking about that
nkohari: he suggests creating query objects
nkohari: which is actually a very good idea
evarlast: if you look at the whole NH Criteria API, its mostly duplicate of what is now available with Expression<> in 3.5
nkohari: evarlast: that's the idea
mjeaton: someone raise d a good question: one repository or multiple?
nkohari: it's a linq provider...
RossCode: nkohari: I'm not saying it's bad. I think I would rather encapsulate how I get my data in a repository and have hte controller call the repository
nkohari: RossCode: you can definitely do that
nkohari: the other argument is that you have one 'data context' that provides low-level access to the IQueryable<T>s
nkohari: and then you build repositories on top of that
mattsonlyattack: one repository per aggregate root is the standard response
nkohari: bradwilson was advocating that on twitter
mjeaton: mattsonlyattack: don't want standard response. i want to know what you guys are doing.
nkohari: mattsonlyattack: yeah, there's more flexibility there for sure
Ang3lFir3: mattsonlyattack: define aggregate root.... cuz no one has done that very well yet
RossCode: nkohari: that makes sense - so public repositories all talk to one lower level repository?
RossCode: Ang3lFir3: have you watched the DDD chalk talk by bsimser?
nkohari: RossCode: yeah, the data context is just an object with a bunch of IQueryable<T> properties
mattsonlyattack: watching that greg young chalk talk is good for this question
Ang3lFir3: RossCode: yup... he didn't make it clear enough
nkohari: and then you can create a mock one by implementing each with a List<T> (i think?)
mattsonlyattack: it seems he redrew boundries for multiple aggregate roots with the same sets of entities
mjeaton: see, when i hear nkohari go off like that, I think "wow, complexity. is it needed?"
nkohari: mjeaton: nope, it's not
mjeaton: of course, I'm the dumbest guy in this channel right now...
Ang3lFir3: mattsonlyattack: that is supposed to be ok... some aggregate roots are allowed to have the same entities in them... they are supposed to be about concepts i think
JamesBender: mjeaton No you're not.
mattsonlyattack: mjeaton: not the dumbest by a long shot
averyj: If I was building bank sofware, I would do all of this
nkohari: it's not important in all cases
RossCode: mjeaton: depends on how big the project is, I would say
averyj: but I am not, I am building simple software
averyj: so I just need simple solutions
Ang3lFir3: mjeaton: no you aren't
nkohari: if you code against repositories though you get some benefits
mjeaton: averyj++
nkohari: like for example
averyj: ActiveRecord is simple
mattsonlyattack: Ang3lFir3: agreed, the aggregates help w/logical paths to other objects
nkohari: ideavine reads info from xml files right now
nkohari: but eventually we might want to move it to a db
averyj: YAGNI
nkohari: that's ultra-simple with a repository-based approach
averyj: use tests and re-factor
nkohari: i'm not disagreeing with that
averyj: we might never move it though, and now we have un-needed complexity
nkohari: but this approach lets you refactor less
nkohari: not really
mjeaton: all of you need to go to summer camp dammit.
nkohari: what else would i have done?
averyj: I agree we need to design for change, but isn't that what my unit tests are?
mattsonlyattack: mjeaton++
nkohari: private methods that would read the xml?
nkohari: that's not any easier than what i did
averyj: yeah, I can see that
mattsonlyattack: http://weblogs.asp.net/bsimser/archive/2008/08/16/alt-net-canada-day-2-ddd-and-more-d.aspx
Ang3lFir3: my issue in our domain is that while I have entities of the same types...the definition of those entities is different for all implementations
averyj: the repository for getting the XML makes sense because you had to have something to do that
nkohari: i guarantee, once you grok DI this stuff doesn't sound nearly as complex
averyj: and that is a good simple pattern
JamesBender: nkohari++
averyj: Its not the complexity that bothers me as much as the obfuscation of the code
nkohari: i just naturally smash this stuff out now
nkohari: averyj: that's true
nkohari: that's why i favor [Inject] actually
averyj: It is way harder for me to grok an application like that, especially when there are levels and levels of stuff being injected
RossCode: averyj; I agree- that's one of the problems I have with interfaces for everything
After a short lull (not fit to be reprinted here), James Avery got the conversation back on track.
averyj: ok, repository question for the room. I actually did a 2 year project using the pattern we are talking about but we used a generic Repository, what the reason to have a separate CustomerRepository?
nkohari: averyj: you can wrap queries inside the repository
nkohari: er, customerrepository
mjeaton: so, IRepository<T> vs. IFooRepository?
nkohari: queries with business logic in them, like GetAllLoyalCustomers()
averyj: we actually had just one Repository and it had stuff like Save<>
averyj: its the one Dave made open source
averyj: NHibernateRepository I think
nkohari: yeah
mjeaton: averyj: yea, we used that on a project.
evarlast: Save<> ? that is horrible
averyj: actually based on Bellwares code from like 4 years ago
RossCode: averyj: where do you put code for things like GetCustomersByFirstName?
averyj: on this project we had separate data objects when we needed them
TheProkrammer: Customers.Find( c => c.FirstName = "value")
TheProkrammer: err ==
averyj: but I could see that, use CustomerRepository for the custom queries
RossCode: TheProkrammer: in your controllers?
averyj: so yo have a base repostiory it all inherits form?
TheProkrammer: bah, I'm working here, stop making me think.
RossCode: averyj: I laid out what I did in a blog post just last night
RossCode: I used an interface and extension methods
mjeaton: RossCode: link?
RossCode: http://www.rosscode.com/blog/index.php?title=playing_with_nhibernate&more=1&c=1&tb=1&pb=1
RossCode: Note: I've been playing with NHibernate for 1 week, so i could be completely off base. I probably am
averyj: intereting, why not use a base class?
RossCode: testing, mainly. Since it's interface based, I can use Moq to mock the repositories
averyj: you can still have an interface
averyj: just thinking instead of the extension methods you could haev a base class
qrush: Moq?
averyj: I could be missing something though
RossCode: so have CustomerRepository: IRepository<T>, BaseRepository?
mattsonlyattack: qrush: http://code.google.com/p/moq/
RossCode: I think I tried that, but then BaseRepository has no knowldege of T
mjeaton: Moq is cool, but people tell me Rhino caught up with the features.
RossCode: I guess I could have made it BaseRepository<T>
qrush: but seriously. lots of new libs using 3.5
qrush: i need to try it someday :/
RossCode: mjeaton: I saw the new syntax for Rhino recently - very similar to Moq's syntax
RossCode: I picked Moq before I saw the new way Rhino works. The old way looked too complicated for me
mjeaton: wishes he was sitting with rosscode, averyj and a laptop right now.
mjeaton: RossCode, agreed. The record/playback stuff was crap.
mattsonlyattack: which was still in moq, just implied by the syntax
mjeaton: right.
mattsonlyattack: moq is still sexy
RossCode: You guys are ruining my day. I'm supposed to be working. How am I supposed to prepare for the fantasy draft tonight?
This is the power of the tribe - impromptu discussions on just about any topic. It's guaranteed to generate a conversation. Want to be part of the next one? Stop by - we'll be there!

Categories: Development
Playing With NHibernate
posted on 08/27/08 at 11:52:42 pm by Joel Ross
Over the past week or so, I've been dabbling with NHibernate. As may be apparent from reading my latest posts over the past few weeks, I've been digging into automated testing more and more, and as I've looked at how I can make the Kinetic Framework more testable, I decided to look elsewhere to see how others are doing it.
NHibernate is probably the most popular ORM tool in the .NET space right now, so it was the obvious place to turn. It's been around for a long time, and it's a tool that's been on my list to learn for a while.
As it turns out, it's actually not that bad to get working. To be honest, I was intimidated by the XML configuration files, but I dove in and eventually figured it out. I started with a very simple object model - the beginnings of a side project I've been thinking about starting. It has four tables - Games, Teams, Weeks, and Seasons. The intent of these tables is to be able to build a schedule for the NFL. You'll see the data I'm storing as we explore the objects further, but I do have a few relatively complicated relationships here. Seasons have a collection of games (by week), and Games are made up of a Season, a Week, a Home Team and an Away Team.
The models themselves are pretty much POCOs. For example, here's my Team class:
1: public class Team
2: {
3: public virtual int TeamId { get; set; }
4: public virtual string Abbreviation { get; set; }
5: public virtual string Location { get; set; }
6: public virtual string NickName { get; set; }
7: }
Like I said - there isn't much there. The virtual keyword is required by NHibernate (as is a default constructor - I didn't include it, but it's implied).
The part I was most worried about was the mapping files. In reality, the mapping file is more complicated than the object itself, but it's not that bad. Here's the Team object mapping XML:
1: <hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="CP.Models" namespace="CP.Models">
2: <class name="CP.Models.Team" table="Teams">
3: <id name="TeamId" column="TeamId" type="Int32" unsaved-value="0">
4: <generator class="native" />
5: </id>
6: <property name="Abbreviation" column="Abbreviation" type="string" length="50" not-null="false"/>
7: <property name="Location" column="Location" type="string" length="50" not-null="false" />
8: <property name="NickName" column="NickName" type="string" length="50" not-null="false" />
9: </class>
10: </hibernate-mapping>
There's a few interesting things here. First, the Id element. This defines how a Team can be identified from other teams. In my database, it's an auto-number int, and I want to allow my database to manage the numbering. First, I map my identifying property to TeamId, which maps to TeamId in the database. The generator specifies how NHibernate should figure out what a new Id should be. "Native" tells NHibernate to pick the best method for getting the id. In this case, it'll let the database handle it. The other property elements are pretty straightforward - just how each property on my Team class is mapped to the database, it's type, whether it can be null, and it's length.
The interesting (and intimidating) part of the mapping files is more evident when we look at the Game class.
1: public class Game
2: {
3: public virtual int GameId { get; set; }
4: public virtual Week Week { get; set; }
5: public virtual Season Season { get; set; }
6: public virtual Team HomeTeam { get; set; }
7: public virtual Team AwayTeam { get; set; }
8: }
The game class shows it's relationships. How those manifest themselves is evident through its mapping file, which is a bit more complicated.
1: <hibernate-mapping xmlns="urn:nhibernate-mapping-2.2" assembly="CP.Models" namespace="CP.Models">
2: <class name="CP.Models.Game" table="Games">
3: <id name="GameId" column="GameId" type="Int32" unsaved-value="0">
4: <generator class="native" />
5: </id>
6: <many-to-one name="Week" column="WeekId" not-null="true"
7: fetch="join" outer-join="false" cascade="save-update" />
8: <many-to-one name="HomeTeam" column="HomeTeamId" not-null="true"
9: cascade="save-update" fetch="join" outer-join="false" />
10: <many-to-one name="AwayTeam" column="AwayTeamId" not-null="true"
11: cascade="save-update" fetch="join" outer-join="false" />
12: <many-to-one name="Season" column="SeasonId" not-null="true"
13: cascade="save-update" fetch="join" outer-join="false" />
14: </class>
15: </hibernate-mapping>
The Id element is the same as above. The difference is that instead of properties, this object has other objects as part of it - the many-to-one elements. Each element maps to a property on the Game class, and specifies which column in the Games table to get the Id for the related object. The rest specify how it should get the data (I think - I got this working, and didn't look at it too much further yet).
Once I created all of the classes and created the mapping files (and the hibernate config file, which I won't show), it's just a matter of starting up the NHibernate configuration. At some point, I saw the idea of a helper class that you can use to get new NHibernate sessions, so that's what I went with.
1: public class NHibernateHelper
2: {
3: private static ISessionFactory _sessionFactory;
4: private static ISessionFactory SessionFactory
5: {
6: get
7: {
8: if (_sessionFactory == null)
9: {
10: var configuration = new Configuration().Configure();
11: configuration.AddAssembly(Assembly.GetExecutingAssembly());
12: _sessionFactory = configuration.BuildSessionFactory();
13: }
14: return _sessionFactory;
15: }
16: }
17:
18: public static ISession OpenSession()
19: {
20: return SessionFactory.OpenSession();
21: }
22: }
The first time this code gets called, it sets up NHibernate, and tells it to look for configurations in the executing assembly (which contains both the mapping files as embedded resources and the models themselves). Once done, I can just call NHibernateHelper.OpenSession() and get a new session for working with my objects.
Once that was done, I started building repositories to talk to NHibernate to do the retrieval. I'm new to the Repository pattern, but based on a bit of research and a few samples, I came up with a base interface:
1: public interface IRepository<T> where T : new()
2: {
3: T Create();
4: T GetById(int id);
5: void Save(T model);
6: void Delete(T model);
7: ICollection<T> GetList();
8: }
I think, as I build this out more, I'll add more methods (or at least overloads to existing ones) that allow me to run queries, but for each object, I'll have a concrete implementation of the IRepository<T> interface for it. But the implementation for a lot of these methods will look very similar and have to deal with the details of sessions in NHibernate. For each of my repositories, I didn't want them to have to inherit from a base class that implements the interface, so I came up with a set of extension methods that handle the interface methods. Here's an example of the Delete() extension method:
1: internal static void Delete<T>(this IRepository<T> repository, T model) where T : new()
2: {
3: using (ISession session = NHibernateHelper.OpenSession())
4: {
5: using (ITransaction transaction = session.BeginTransaction())
6: {
7: session.Delete(model);
8: transaction.Commit();
9: }
10: }
11: }
This doesn't actually satisfy the interface requirements (I'm not sure an extension method even can do that), so in my repositories, I still have to make a call. Here's the call for delete in the TeamRepository (which implements IRepository<Team>):
1: public void Delete(Team team)
2: {
3: this.Delete<Team>(team);
4: }
Now, I can create new repositories quickly, and my physical implementation doesn't have to worry about the NHibernate details. Interestingly (and only in theory, since I haven't tried it), I could switch out extension methods, and switch which ORM tools I am using, since the only references to NHibernate is in the extension methods and the NHibernateHelper class (which, in turn, is only used by the extension methods).
Once this is all done, retrieving data is pretty simple. My sample application is written using the ASP.NET MVC framework, and my TeamController has a List method that's just this simple:
1: public ActionResult List()
2: {
3: return View(Repository.GetList());
4: }
That's it! I can get the data I need, without ever writing any data access code.
It's tough to compare this to the Kinetic Framework, as I still have some learning to do. The sheer amount of code I have to deal with is considerably less with NHibernate, but the majority of the code in the Kinetic Framework is generated, and not really something I have to maintain. This method does lend itself to being able to write automated tests for it, since I can mock the repositories easily, which is not easily accomplished in the Kinetic Framework (although a Repository pattern can be placed on top of the Kinetic Framework to do this).
I'll post more about my experimentations, but so far, I like NHibernate a lot. I'm still learning the ropes, and would like to know how the query is working - for example, when I get a game, does it retrieve the home team, away team, week, and season all in one query, or does it lazy load the properties as needed? I'll find that out, but I just haven't had the time yet.
Regardless, it's nice to use a solid framework and not have to worry about the ugly details underneath (or at least not have to be the one to maintain the ugly details!)
Categories: Development, Software, C#
How Many Levels of Abstraction Do You Care About?
posted on 08/24/08 at 11:16:01 pm by Joel Ross
There's been a lot of discussion on twitter recently about Drag-N-Drop (DND) software development, and whether or not that's good for the industry as a whole. Personally, I think it clouds the whole process by making it appear too simple, when in reality, we all know it's not that easy.
But it did get me thinking. DND and designer-based software development in general is really just about abstracting away the need to understand the code that is needed to place an element on a page away from the developer. And that's not necessarily a bad thing by itself. Abstracting away details is what makes software development easier. As a .NET programmer, I have yet to run into a situation where I truly cared about the IL my code generated. I've looked because I was curious, but at the end of the day, I didn't really care. And I definitely don't care how that IL becomes machine language, or how the OS handles that machine code.
Why don't I care about those abstractions, but I do care about the abstraction that DND coding provides? Because the abstractions I just mentioned aren't leaky. The DND example? It leaks. It leaks bad. And that's the main problem with DND - it's not inherently bad, it's that you have to have intimate knowledge of what is going on beneath the covers. The DND tools aren't to a point where they can completely abstract away the details from you, so what ends up happening is you spend more time in the details trying to figure out what the DND tool did (and why!) then it would take to just re-write the whole thing.
And that's when things get tricky. It's not the initial development - that part appears to work well. It's when you have to maintain the code because a requirement changes or a bug is found. Dropping a grid and binding directly to the database is simple initially, but what happens when you need to add a new field, and that's not easily bound to a database column? Things start to get a bit hairy, and you're left digging through lines and lines of generated code ("This code generated by a tool" is one of my favorite comments, by the way) to try to figure out what is going on. Or worse, you have to figure out if you can even do what's being asked of you with the current implementation. You might just have to start over!
And that's what makes DND development dangerous. It's dangerous in two ways. First, when it's demoed, it's viewed as being The Right Way to develop software, and while some of us realize that software development can't be done through a series of drag and drop components, some don't. We call them "Managers" and they wonder why a software project will take six months when you can just drag stuff around and make it work. Second, when you listen to your manager and you start to create software thinking that DND is the way to develop, you're left with unmaintainable code. Yeah, you impressed your manager with how fast you put together the new website, but now he has a few changes that he expects to be made just as quickly. Suddenly you realize how hard the current situation is to maintain, and you're left in the same spot - why are your changes taking longer than the initial development?
Some day, I would expect that DND tools will be sufficiently advanced that you can rely on them for both initial development as well as maintenance. The need to dig into the generated code will be eliminated, and the feature set available through DND will be on the same level as what's available today when you write code by hand. But that's not the case yet, which is why I cringe when I see people creating production level applications by dragging and dropping components and wiring up applications through a designer.
I know someday, I'll have to maintain it, and I can only hope that the tools have advanced far enough that I can do that easily.
Categories: Development, C#
Opportunistic Advertising?
posted on 08/15/08 at 12:44:14 am by Joel Ross
I spend most of my day in an IRC chat room (##twittertribe on irc.freenode.net - stop by and say hi sometime!), just kind of lurking to see if anything interesting comes along. Every now and then, I'll find a link worth clicking on. Today was one of those days, and I'm not sure why it caught my attention. It was an article about a Netflix outage, and I'm not even a Netflix subscriber!
Anyway, I was amused when I got there and saw this:

Talk about opportunistic ad placement!
Categories: General
Querying in the Kinetic Framework
posted on 08/14/08 at 08:00:00 pm by Joel Ross
I was chatting with a few people in IRC the other day about different development approaches, and I brought up the Kinetic Framework. Someone took a look at source of the samples and didn't care for the SQL included in the class files.
Personally, I don't have a huge problem with it, but I understand the concern that others have. It definitely violates separation of concern, instead favoring encapsulation. Good or bad, that's the way it is.
But the more I thought about it, the more I wondered how hard it would be to create a simple interface to create your own queries easily. And then I started building it. By the time I was done, I had a solution in place that allowed me to create all of the queries created by the Kinetic Framework, and cover the majority of custom cases. And it has at least a bit of a fluent interface!
For custom queries, this is what we had before (this is from an example of getting a game with team's real names - there's a number of joins in there):
1: string commandText = @"
2: select " + Game.SelectFieldList + @",
3: [" + Week.TableName + @"].[Number] as 'WeekNumber',
4: ht.[Location] + ' ' + ht.[NickName] as 'HomeTeamDisplayName',
5: at.[Location] + ' ' + at.[NickName] as 'AwayTeamDisplayName'
6: from [" + Game.TableName + @"]
7: inner join [" + Week.TableName + @"]
8: on [" + Game.TableName + @"].[WeekId] = [" + Week.TableName + @"].[WeekId]
9: inner join [" + Team.TableName + @"] ht
10: on [" + Game.TableName + @"].[HomeTeamId] = ht.[TeamId]
11: inner join [" + Team.TableName + @"] at
12: on [" + Game.TableName + @"].[AwayTeamId] = at.[TeamId]
13: where [" + Game.TableName + @"].[SeasonId] = @SeasonId
14: order by [" + Week.TableName + @"].[Number] asc;
15: ";
16:
17: List<IDataParameter> parameters = new List<IDataParameter>();
18: parameters.Add(ServiceLocator.GetDataParameter("@SeasonId", season.SeasonId));
19:
20: return EntityBase.GetList<FullGame>(commandText, parameters);
Notice the large string built and manually working with parameters. Lots of SQL syntax knowledge involved here.
Compare that to the way I came up with:
1: JoinCriteria joinCriteria = new JoinCriteria(typeof(Game), typeof(Week),
2: Game.GameProperties.WeekId, Week.WeekProperties.WeekId)
3: .Add(new JoinCriteria(typeof(Game), typeof(Team),
4: Game.GameProperties.HomeTeamId, Team.TeamProperties.TeamId, "ht"))
5: .Add(new JoinCriteria(typeof(Game), typeof(Team),
6: Game.GameProperties.AwayTeamId, Team.TeamProperties.TeamId, "at"));
7:
8: ICriteria criteria = new StandardCriteria(typeof(Game), Game.GameProperties.SeasonId, 1);
9: IQueryContainer query = (new QueryGenerator(typeof(FullGame), criteria, joinCriteria)).GetQuery();
10: return EntityBase.GetList<FullGame>(query.CommandText, query.Parameters);
I'm not sold on the exact semantics yet, but the idea is there. This doesn't require any SQL knowledge. You still have to know how your objects are related, but not SQL directly, and you don't have to worry about creating your own parameters. The QueryGenerator handles creating the query for you, and as it builds the query, it maintains the parameters as well.
The other nice thing about this is that, while it is meant to work with the Kinetic Framework, it doesn't require any changes to the framework to work - it's essentially an add-on that I could plug into any of my existing projects and immediately get the benefit of being able to build queries quickly and easily.
I've also been messing around with the ASP.NET MVC bits as well. I'm trying to figure out how I could use that with the Kinetic Framework, and be able to unit test the controllers. Because of all of the static Get methods, that's tough. So I've been messing around with the idea of adding Repositories to handle the actual retrieval and persistence of the entities. It's still a bit awkward, but I was able to unit test my controllers without ever hitting any of the static methods or any persistence methods in the framework - because I was able to mock my repositories. I need to tighten that up a bit, but I'll probably blog about that a bit in the future. Actually, the above querying technique makes the repositories easier to create and less coupled to the static methods in the entities - a good thing. But that's for another time.
So, if you use the Kinetic Framework, would this be something you'd be interested in? It still needs a lot of work, but I wanted to see if there's any interest in it before I pursue it too much.
Categories: C#, RCM Technologies
Simple Online CMS
posted on 08/13/08 at 08:00:00 pm by Joel Ross
Ever since I started this site, I've been trying to figure out a way to simply manage a few items and pages - such as my about page. I know I could have done a blog post that included my about information, and then just linked to that, but it seemed like a hack, and the URL wouldn't be as clean.
So I created a static page - well, relatively static. It's still a page using my blog's template, but the main content area is static content instead of code that pulls in blog posts. But even so, it's a pain to maintain. I have to edit locally and then upload the files. And it's all maintained in a virtual machine, so it's even more of a pain.
Ok. So it's not that bad. I'm just lazy.
But the other day, I saw a tweet from Cisco, a fellow RCMer, mentioning CushyCMS. You see, Cisco's a designer who is very good at what he does, and if he's saying something is good, that means it's well designed, has good usability, and doesn't take any technical knowledge whatsoever.
Yeah, yeah. That last one wasn't fair. But in this case, it's true. CushyCMS offers you online HTML editing of any page on your site. It's simple to set up and it works well. I have one page under its control now, and am thinking of adding others - or at least parts of others.
What it's actually doing is pretty simple - it uses FTP to push the file back to the server. But the ability to edit online from anywhere in a WYSIWYG fashion is killer. And I can segment my page anyway I want - just add a class="cushycms" to any element and it's editable. Below, I've added the class to an H3 (About RossCode.com), a div around some content, and then to another H2, and an H3 below that. They all show as editable areas:
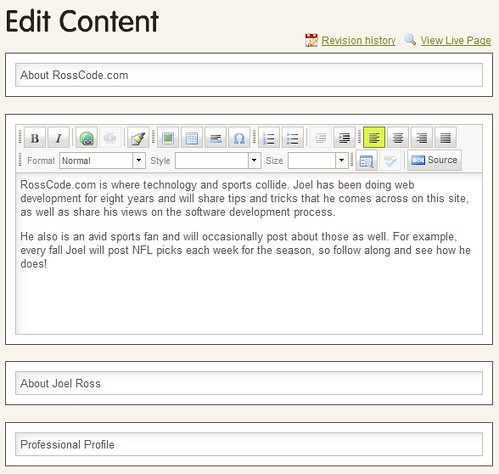
In the past, I've hesitated to add a blog roll to the sidebar, because it's too difficult to maintain - or really any manually maintained areas there that I would want to change. But now, I could add some of those types of features and manage them easily, preventing them from getting out of date.
As I was writing this post, I was also tweeting my experience. Nathan Bryan responded that it's a problem when you keep files under source control. While this is true, I think some of it depends on how you use it. If you're adding CushyCMS directly to your code files, then yeah, that's a problem. But CushyCMS recommends against that anyway, instead recommending that you store the content you want to edit in a static file by itself. Then you just include that content in the dynamic page where you need it. To me, this isn't really that much different than storing your content in a database - something most CMS systems do - and then working out a backup process for those custom files.
CushyCMS probably isn't something to use for a large site, but for small, one-off solutions, it looks like a good, easy to integrate solution that solves a common need.
Categories: Software
Getting Started With Mocking and Moq
posted on 08/08/08 at 12:45:40 am by Joel Ross
Lately, I've taken a keen interest in unit testing. I've started to rewrite some of my code to make it more test-friendly. One of the frustrating parts about doing that is that I found I was creating a lot of fake classes in my tests so that I would be able to test just a single part of my code, while holding other parts constant.
Maybe it's just because I always envisioned that testing would be pretty simple, but for some reason, having all of those extra (fake) classes around didn't sit well with me. So I decided to look into a mocking framework. Since I was using .NET 3.5 and I'd heard that Moq was built on that, I figured I'd give that a go. It's worked out quite well.
Imagine that I have a User class:
1: public class User
2: {
3: public FirstName { get; set; }
4: public LastName { get; set; }
5: public UserName { get; set; }
6: public Password { get; set; }
7: public Email { get; set; }
8:
9: public User() { }
10:
11: public bool EmailPassword(IEmailSender emailSender)
12: {
13: string subject = "Your Password";
14: string body = String.Format("{0} {1}, your password is {2}", FirstName, LastName, Password);
15: return emailSender.Send(subject, body, Email);
16: }
17: }
One of the things you'll notice about code written to be tested is that it's very modular, so when a user requests their password, the User class doesn't know anything about how an email is sent - it just uses an interface, and it's up to the calling application to supply that. If you start to write all of your code this way, you'll quickly see the usefulness of using a dependency injection framework (such as Ninject) to handle resolving your dependencies for you. But that's not what I'm focused on here. As a matter of fact, I don't care about the actual implementation of IEmailSender that the application will use. All I care about is the interface:
1: public interface IEmailSender
2: {
3: bool Send(string subject, string body, string email);
4: }
If I want to test the EmailPassword method, I have a couple of options. I could create my own mock email sender and implement the Send method and have it return true. But what happens when I want to test what happens when it returns false? Or it throws an exception? Now I'm starting to write a lot of code in a fake implementation, strictly for the purpose of testing. While I think the benefits of doing that are there, I also think there's potentially a better way.
The second option is to use a mocking framework. When you work with a mocking framework, what you're doing is essentially implementing the interface on the fly, and telling it what it should return when methods are called. Let's look at an example of a test that just verifies that EmailPassword returns true when emailSender returns true:
1: [Test]
2: public void User_Can_Send_Password()
3: {
4: var emailMock = new Moq.Mock<IEmailSender>();
5:
6: emailMock
7: .Expect(sender => sender.Send(It.IsAny<string>(), It.IsAny<string>(), It.IsAny<string>()))
8: .Returns(true);
9:
10: User user = new User();
11: Assert.That(user.EmailPassword(emailMock.Object) == true);
12: }
Line four says that I want to create an implementation of the IEmailSender interface, so I can use that later in line 11, when I call EmailPassword. Notice the .Object - that's the dynamically created IEmailSender. Lines six, seven and eight are the meat of the mock. Line seven sets up how the mock should expect to be called. Any time Send is called, passing in any string for any of the parameters (the It.IsAny<string>() code), line eight specifies that it should return true.
Now if we wanted to verify that EmailPassword returns false when IEmailSender.Send returns false, it's just a matter of taking the above code and changing line eight to .Returns(false). Each test sets up the mock the way it wants, so the mock is isolated across tests. There's no need for any extra logic to determine what should be returned in scenarios beyond the scope of that test, like there would be if I created an actual MockEmailSender to cover all of the different cases.
There are different options with the expects (in line seven) to allow you to match that the correct parameters are passed as well. You can also add a .Verifiable() on the end of the mock setup code and then call emailMock.Verify() after you run your test code (so, after line 11) and verify that the method was actually called.
I'm still fairly new to Moq and mock objects in general, but so far, I'm impressed with what I've been able to do and how quickly I can do it.
Categories: Development, C#
An Interesting Summer Ahead
posted on 07/24/08 at 12:55:37 am by Joel Ross
A little over a week ago, The Wife headed out to the garage to get us some dessert. When she came back into the house, she was pretty excited - she found some moose tracks ice cream - and she came flying up our back stairs (there's 4 of them).
"Joel! I just broke my foot!"
I looked toward the back of the house, and she was standing on the stairs - on one foot, holding the other one. She can be a bit dramatic, so I didn't think too much of it. She tells me that she's broken a bone on a fairly regular basis, and after "toughin' it out" for a little bit, it's usually just fine.
But this was different. She wasn't putting her foot down, and she wasn't moving. So I headed down there and helped her to a stool in the kitchen. Then I went to get a neighbor to help get her to the car. We had the neighbors watch the kids (I love my neighbors - they are ALWAYS willing to help us out when in need), and we were off the ER.
Once at the ER, I got to hear what happened from her perspective. Get ready to cringe. As she was coming up the steps, she felt her foot start to slip (she was in a pair of flimsy flip-flops). This isn't anything new for her, but usually she slips down and bangs her shin on the step. She didn't want to hurt her shin again, so she gripped down on her foot. But she wasn't fully on her foot - just the end of her foot was step. She pushed down, and when she was done, she knew something was wrong. When she looked down, she could see her bones sticking up in her foot. Not through the skin, but she knew it wasn't right. Before the pain kicked in, she reached down and pushed the bones back into place!
After 4 long hours, excruciating pain (she said this was the worst pain she ever felt, which is telling given that she's given birth to three kids), X-Rays and a CT, the doctors came to the same conclusion it took my wife two seconds to come to: Her foot was indeed broken. The prognosis was basically that she folded her foot in half. She was given some Vicodin and a splint and sent home on crutches.
We went to a local doctor a few days later. He essentially told us that she broke bones in 5 places and would be off her foot for 3 months, but no surgery at this point. They'd re-evaluate on a bi-weekly basis, and with that, we were done - 5 minutes with the doctor. The Wife wasn't comfortable, so we decided to get a second opinion. In that five minutes, he did tell us that it was "a very bad and very serious injury" so we felt justified getting a second opinion. Of course, we were pretty sure it was a bad injury since, you know, you're not meant to fold your foot in half!
The second doctor was far, far better than the first. He sat with us for about an hour explaining everything. We actually got to see the X-Rays - he was impressed that the ER picked up on what happened, but his diagnosis was completely different than the other doctor's. He said that yes, there were either 4 or 5 bones broken, but that wasn't the concern. Those would heal as part of treating the real issue. What she actually did has a name: The Lisfranc Injury. Apparently it's actually quite often missed in diagnosis - that article says as many as 20% are missed.
He gave her two options - surgery or no surgery. He gave us all of the pros and cons of each, and left it up to her. He said she would never forget that she broke her foot, and that most likely, it would never be solid enough to withstand the rigors of the NFL (his examples of other people who had the same injury were Duce Staley and Aaron Brooks), so I guess that means her NFL career is over! The good news was that he thinks the recovery time (surgery or not) would be 6-8 weeks, rather than 12. And he made it more comfortable for her to sleep. Based on the pros and cons, she opted out of surgery, and I think it's a good decision.
While she's healing, she's essentially stuck on the couch. She can't put weight on it, and using the crutches requires two hands. She can't really pick up or carry our 11 month old son, who is taking it pretty hard - mommy can't be mommy right now. Frankly, it's hitting all of us pretty hard, but we'll make it through.
One last thing: I told my oldest it was time for bed the other night, and that she had to get off the cough. She told me she couldn't because "mommy's crotches are in the way." I'm almost positive she meant crutches!
Categories: Personal
The NuSoft Framework Is Now The Kinetic Framework
posted on 07/16/08 at 09:32:59 pm by Joel Ross
One of the first questions I got when people heard about RCM bought NuSoft Solutions was whether we were going to be renaming the NuSoft Framework. At the time, I had no idea, and frankly, it was about as far back in my mind as it could be.
Well, the acquisition is three months in the past, and we're starting to integrate things tighter now. As part of that, there was concern about brand confusion with RCM using and sponsoring the NuSoft Framework. So, the decree came down to rename the framework.
Which we did. Since we've started a new group - Kinetic IG - it was only natural to lean towards the Kinetic Framework, but that's not the only reason we settled on that name. The framework has two important aspects that relate to the word "Active" (of which Kinetic is a synonym). First, it uses the Active Record design pattern for it's entities. Second, it relies on active code generation - the majority of the code generated can be re-generated if your data model ever changes without wiping out any custom code you may have. Given those things, combined with the idea of kinetic having to do with motion and momentum, we felt it was a good name.
We've updated the CodePlex address to http://www.codeplex.com/KineticFramework, but the old address does redirect to the new one. I am in the process of changing all of the content and source to reflect the name change - I would expect to be done in the next few days.
As far as framework development goes, not much has been going on. I have been playing with it a bit to make it more testable, but nothing official yet. More on that if I ever get it to a place where I'm happy with it.
Categories: RCM Technologies