
Testing the NuSoft Framework
posted on 07/09/08 at 12:45:25 am by Joel Ross
 I've started up a new project that is using the NuSoft Framework, and because of some of the interactions, I realized it would be much, much easier if I had a set of automated tests, rather than going through the process of firing up an application, going through a WCF service, and then eventually hitting the code I needed to test.
I've started up a new project that is using the NuSoft Framework, and because of some of the interactions, I realized it would be much, much easier if I had a set of automated tests, rather than going through the process of firing up an application, going through a WCF service, and then eventually hitting the code I needed to test.
I realize this isn't earth shattering for those used to doing TDD or unit testing, but it's not something that I've done a lot of in the past. On one project, we had well north of 100 tests, but they were all isolated to a particular hairy part of the code and it was rather self-contained.
To be honest, the NuSoft Framework is not ideal for unit testing, since the data persistence is pretty well embedded into the entities. That's OK in my mind, since I've rarely seen a case where my persistence layer has changed. Once, I knew I had to build for different databases, but that was known up front, and not added after the fact. That may be viewed as a naive attitude, but it's worked for me so far.
Anyway, there's a reason I didn't call this "unit testing" but rather referred to it as just testing. It's not unit testing, since it's not testing just one thing. It's more like an integration test, since it's also going to rely on a known state of the database.
Essentially, what you have to do is manage your own transaction, and then at the end, after you assert that your desired action worked, you roll it back, leaving the database untouched. If you want to isolate your tests in their own assembly, you're going to need to add an attribute to your business layer so you can gain access to some of the internals of the business layer:
1: [assembly: InternalsVisibleTo("Northwind.Tests")]
This gives us the ability to call one of the internal overloads on Save() where you can pass in a helper. This ensures the Save will participate in the existing transaction, and not create its own (which it does when you call Save() with no parameters). Here's an example that would test being able to insert a customer:
1: [Test]
2: public void CanInsertCustomer()
3: {
4: Customer customer = Customer.CreateCustomer();
5: customer.CustomerId = "jross";
6: customer.FirstName = "Joel";
7: customer.LastName = "Ross";
8:
9: using (SqlHelper helper = new SqlHelper())
10: {
11: try
12: {
13: helper.BeginTransaction();
14: customer.Save(helper);
15: Assert.That(customer.IsNew == false, "customer.IsNew was true but should have been false.");
16: }
17: finally
18: {
19: helper.Rollback();
20: }
21: }
22: }
The difference between this code and the code you would normally use is that you wouldn't manage your own helper and you'd call customer.Save(), not customer.Save(helper). If you dig into the guts of Save() with no parameter, you'll see it does essentially what I'm doing here. It creates a SqlHelper and opens the transaction. The difference is that if the insert works, the transaction is committed, and here the transaction is always rolled back, ensuring that the database isn't affected and leaving it in a known state for other tests.
I'm still new to automated testing, but it definitely does make being able to change existing code much easier and give me more confidence when I am doing that. And seeing all of the green lights in NUnit feels pretty good too.
Oh - the NuSoft Framework has a logo now (the one at the top of this post). What do you think of it?
Categories: Development, C#, RCM Technologies
Grand Rapids Tech Lunch – Monday July 7th
posted on 07/01/08 at 09:26:45 am by Joel Ross
The second Grand Rapids Tech Lunch has been announced, and it'll be at the Grand Rapids Brewing Company on July 7th at 12:00 PM. We have their private room reserved, so it should be a bit quieter than last time, and maybe we'll all fit around the same table!
I'll be there, and hope to see a few people from the West Michigan area there as well!
Tags: GRTechLunch
Categories: General
The Saga of the Dell D820 and 4 Gigs of RAM
posted on 06/30/08 at 09:35:29 pm by Joel Ross
Two summers ago, I got a new laptop - the Dell Latitude D820, a nice dual core machine that works great for what I do - software development. The only issue I had with it was RAM. It came with 2 GB, but that wasn't enough for me. I do all of my development in Virtual PC, and sometimes have 2 or 3 open at a time. Even with only dedicating 512 MB RAM to the virtual machine, my laptop would grind to a halt.
So I upgraded to 4 GB - the price was great ($200 for 2 2 GB sticks). After installing it, I was a bit disappointed to see that the BIOS only exposed 3.325 GB to the OS, but still - I had an extra 1.325 GB of RAM, and I could run 2 VMs, with each getting 1 GB RAM - and the machine still responded well. I figured eventually there'll be a BIOS update or something that would allow me to get that last bit of RAM!
Well, a couple of weeks ago, that BIOS update was supposedly released. It wasn't verified, but word was that the A09 revision could give you access to the full 4 GB. After a bit of a hassle (Ok - it was a MAJOR hassle, but that's not the point here), I got it installed.
So did it work? I honestly don't know yet. I checked Task Manager, and this is what I see:
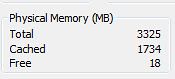
I saw this (Total still at 3.325 GB), and was mildly disappointed. Not shocked, but disappointed. I found an article that talked about enabling PAE, and then it showed (after you enabled it) a screen shot that you can get by right clicking on "My Computer" that shows the full 4 GB. So I tried that. This is what I see:
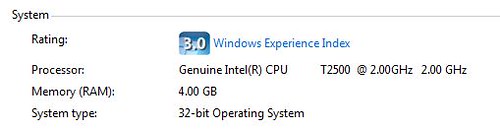
So now, I'm confused. Do I have 4 GB or not? I know what I want to believe, but what's the reality?
NuSoft Framework Now Included with CodeSmith 5.0
posted on 06/29/08 at 08:00:00 pm by Joel Ross
CodeSmith announced recently that version 5.0 is in beta, and one of the features listed is that it now includes the NuSoft Framework right in the download! That's pretty exciting, as we never expected that when we first started writing our templates.
There's actually a whole bunch of templates included now, including NHibernate and .NetTiers ones. I've found that the templates are a great source of sample code to write your own templates - mess around with them and figure out exactly how someone else solved the problem you're trying to solve.
The feature I'm really excited to try out is the source control integration - that running CodeSmith projects from within Visual Studio will cause checkouts to occur. That's a nice change, and will make it easier to keep my generation right inside of Visual Studio - something that I hadn't been doing.
It's still in beta, but I plan to give it a go soon - and provide feedback for one of my favorite development tools.
via Rob Howard
Tags: CodeSmith | Code Generation | NuSoft Framework
Categories: Development, Software, RCM Technologies
War Room and Their Proper Place
posted on 06/26/08 at 08:00:00 pm by Joel Ross
 The other day, Matt Blodgett made a few comments about War Rooms, wondering whether they were actually helpful, or if they did more harm than good. In the interest of full disclosure, I should mention that I work with Matt at RCM, so I have some background on what he's been up to. His project team has been holed up in a room for a few months now. It seems like every time I'm in the office, I see members from his team bringing in supplies (read caffeine, usually in the form of pop - or soda for you southerners!). I stopped by the office on a Saturday, and a subset of the team was there - they're always in there!
The other day, Matt Blodgett made a few comments about War Rooms, wondering whether they were actually helpful, or if they did more harm than good. In the interest of full disclosure, I should mention that I work with Matt at RCM, so I have some background on what he's been up to. His project team has been holed up in a room for a few months now. It seems like every time I'm in the office, I see members from his team bringing in supplies (read caffeine, usually in the form of pop - or soda for you southerners!). I stopped by the office on a Saturday, and a subset of the team was there - they're always in there!
Anyway, I piped up that War Rooms, when used in moderation, can be extremely useful.
Let's back up for a second and look at what a War Room is. I haven't heard the term "War Room" thrown around in software development that much, but we use them a LOT at RCM. So I decided to do a bit of research and see what it means and where it came from. Here's how Dictionary.com defines War Room:
1. a room at a military headquarters in which strategy is planned and current battle situations are monitored.
2. any room of similar function, as in a civilian or business organization.
War Rooms got their start, not surprisingly, in the military. I picture a typical War Room as a group of Generals sitting around a table with each getting information fed to them from the field. Then they share that information with each other, and form a high level strategy that gets sent out to the field to be implemented. The field teams implement the new plan, and report back on progress. The process is repeated, until the war is either won or lost.
RCM is not a military organization, so we're not trying to win any wars. We fall under the second definition, and for us a war room is a room in which strategy is planned and current situations are monitored. Or at least that's the intent is.
In reality, War Rooms, for us anyway, have been used as a place for developers to all work in the same room, so that communication is easier. That sounds good, but in reality, it becomes a distraction, because any major debate results in pulling the whole team into the discussion. Those rarely end well. The discussion usually pits two of the development leaders against each other, and, under normal circumstances, they would work out their differences and present a unified front to the team. When the disagreement is public and in front of the whole team, it makes backing down more difficult. Saving face becomes the priority rather than finding the Right Solution. And no matter what the outcome, the team loses faith in their leadership, because of it's perceived fracturing at the top.
I've been on a couple of projects that have effectively used War Rooms. When they're used correctly, they can have a huge benefit. Some research suggests they can double efficiency. But constantly holing up in a room for months at a time doesn't seem like the best way to me. What we've done is move people's desks to a certain area of the office, so the whole team can be close, but not necessarily stuck sitting around a table. The room is reserved for what a War Room was intended - strategic planning and tactical discussions. We use it to flesh out our plan for the next iteration - high level design with just the parties that need to be involved. Tasks are assigned and then everyone disburses back to their desk to actually do the work. We meet up weekly to sync on tasks and more often if needed for a particular component.
Besides weekly meetings, about the only time the whole team actually gets together in the War Room is after we're pretty much functionally complete for an iteration. Those typically involve lots of back and forth between sub-teams and the QA team. Because of the rapid nature that issues are found and fixed at that point, it's imperative that we're able to work close together. Because the stints are usually short - 2 or 3 days at the most - people don't get burned out being in there, and we usually get a lot accomplished while having a good deal of fun. The free lunches don't hurt either!
The best arrangement for a physical team structure is to have the War Room close to the team's desks. That way, you can quickly get in there, and if the room is dedicated to your team, you don't have to worry about it being used - even if the room sits empty sometimes. It's more difficult if the room is physically separated from your team's desk area, but still workable. Back in the Sagestone days, we had at least one conference room physically close to desks, and we would move teams to that area while the project was going on. At RCM, we don't have conference rooms close to the cube farm, so it makes it more difficult, but we still can move desks to get teams closer, and that definitely helps.
Anyway, I definitely see the value in War Rooms - but I think they are much more effective when used in moderation.
War Room photo courtesy of John Beagle
Categories: Consulting, Development, Software
The Art of Software Estimation
posted on 06/25/08 at 12:35:16 am by Joel Ross
I suck at estimates. I know that, and when I have to do them, I use a spreadsheet that gives me a fudge factor for my numbers. Or, to be more precise, my estimates tend to be how much time it'll take to do the initial development, and there are percentages added on for QA, design, and project management - all of the non-development time that I try not to think about, as well as time for bug fixes (not that there's ever bugs in my code!). I've never really figured out exactly how time is added on (and it changes as new spreadsheets get sent out), but I have been reading "The Mythical Man Month", which is a great book. Anyway, it states that development time is actually 1/6 of the overall time - so my 5 hour estimate should actually result in 30 hours on the project. I'm pretty sure our spreadsheet isn't that extreme, but I also include a bit of design in that development estimate.
To be fair, The Mythical Man Month was written in the 80's (I think) and software development has changed quite a bit since then, so the numbers could be different now. The idea still remains - if done correctly, the development effort shouldn't be the major time sink. But, as I've looked around, there's one thing that I haven't seen included in any estimation system. It's illustrated by a quote from the book.
Extrapolation of times for the hundred yard dash shows that a man can run a mile in under three minutes.
We tend to look at software estimates as successive hundred yard dashes instead of a long distance race. It allows a client to pick out just what they want built, while using their line item veto on tasks they don't want to do. But this assumes that you can break a software system down into features that have no interactions. A series of silos, though, isn't an accurate description of software. There's interactions between features, and rarely do you see estimates take that into account.
This applies to velocity as well. Velocity is the measure of how many features you are delivering over a period of time. When does a project have the highest velocity? My experience has been that it comes right after your base framework is in place and you're building out the first few features. It slows down over time, until the end, when velocity pretty much slows to zero before launch - you're not delivering new features at that point. You're only stabilizing what's already been built.
Why does that happen? Well, to answer that, consider this example. When would it be easier to create an order entry system: Before or after the back-end order fulfillment system is created? It's before, because you don't have to integrate the two processes when the other isn't created yet - you stub it out the way you think it'll work. Even if you do have a task specifically for the integration between the two, it's more time consuming to build something against existing constraints than it is to build something without constraints. And if two teams build them simultaneously, rarely can you just put them together and have it work - there's almost always slight differences in how the two teams interpreted the spec. But the estimate doesn't typically take that into account, meaning there's time to reconcile the differences that isn't in the estimate.
I'm not sure how you would even go about taking that type of time into account. A factor of time that grows as the number of features grows? As the base timeline grows? I don't know. It just doesn't seem logical to think of software development as a series of 100 yard sprints, when in reality, we need to look at it as a marathon - otherwise, it will become a much, much longer and tougher marathon!
When you create your estimates, is it a series of 100 yard dashes, or is it a long distance run?
Tags: Estimation | Mythical Man Month
Categories: Consulting, Development
A Few New Podcasts I’m Excited About
posted on 06/18/08 at 08:00:00 pm by Joel Ross
It seems like everyone and his brother has started some sort of podcast recently, and since I'm an avid podcast fan, I've added a few to my list. The crazy thing about this list is that I knew the people doing each of the podcasts before they started doing it. Maybe not directly, but they are a part of my twitter tribe, which counts in my book!
First up is Deep Fried Bytes. It's hosted by Chris Woodruff, who works with me at RCM, and Keith Elder. It's only had a few episodes so far, but they've all been very good and entertaining. I know these two guys, and I'm looking forward to see what the show becomes. Despite only having three episodes so far, it's produced very professionally.
Next is the ALT.NET Podcast. The more I look at the whole ALT.NET movement, the more I wonder if I would be considered a part of it, for various reasons. But I definitely agree with the premise behind it (if not necessarily it's implementation). The podcast, so far, has been about the part I can relate to, and the guest list so far has been excellent. It's hosted by Mike Moore and he does a great job with it.
The Technology Round Table Podcast (that's as close as a link as I can come up with) is an interesting one. It's a round table (virtual, of course) where they talk about the latest news. It's got four really smart guys on it, and at least right now, it doesn't have a dedicated site or RSS feed. But that doesn't disqualify it! The four smart people are Jon Galloway, Scott Koon, K. Scott Allen and Kevin Dente. They're currently looking for a name, and I think I'm leaning towards "Four Horseman Podcast".
Dime Casts.Net is the only video podcast on the list, and Derik Whittaker's goal is to teach a single concept in under ten minutes. Some of the concepts are pretty simple and some are more complex, but they are all very well done so far. And because it's only 10 minutes long, it's easy to find the time. And even the beginner topics are good reviews for most.
I know there are other new podcasts out there, and I know of at least one on the horizon that sounds interesting, but for now, those four are the ones I'm watching closely right now.
Tags: Podcasts
Categories: Podcasting
Ninject Hits 1.0
posted on 06/16/08 at 09:47:32 pm by Joel Ross
My favorite DI framework, Ninject, has just hit 1.0. Nate Kohari, the author of Ninject, has been working hard on it, and today, announced that it's gone gold. Congrats, Nate!
A few months back, I wrote a post about how dependency injection helped me write code that was more flexible than hard coding the dependencies. In the comments, the discussion of using a framework came up, and I decided to give it a go. I asked what framework I should use on Twitter, and the consensus was Windsor. But later, I had a discussion with Nate, who wasn't around when I asked, and I decided to replace my Windsor implementation with Ninject. It took more time to download Ninject than it did to get it implemented!
Ever since, I've been a huge fan. It's extremely easy to use, and Nate is easy to talk to, and actually listens to your feedback. So, if you're in need of DI (and you should be!), check out Ninject. It's definitely worth your time!
Tags: Dependency Injection | Ninject
Categories: Software
Performance Tweaks For Your Cache
posted on 06/13/08 at 08:00:00 pm by Joel Ross
Over the past few weeks, I've been dealing with a performance issue on Tourneytopia. The site has been working as expected, but it's been a bit slower than I think is acceptable. So we decided to take a look and see if there's a better way to do things that would speed it up.
One of the areas we found was with how we cache data. We cache results fully scored and ranked, which is fine. The problem lies in how we were populating the cache. It's something we would never notice in development, because when you're just firing up the debugger, you aren't running multiple threads against that code. It's only when you hit the same code on multiple threads do you notice the issue. Here's how our cache was working:
1: public List<ScoredEntry> GetScoredEntries()
2: {
3: if(HttpContext.Current.Cache["ScoredEntries"] == null)
4: {
5: HttpContext.Current.Cache["ScoredEntries"] = Pool.GetScoredEntries();
6: }
7: return HttpContext.Current.Cache["ScoredEntries"] as List<ScoredEntry>;
8: }
At first glance, this looks just fine. The first time this code is exercised, the cache is null, so we populate it. Then we return it. Nothing wrong there, right? Well, yes, actually. Pool.GetScoredEntries() takes time to complete. While it's running, what happens if another thread hits this code? The cache is still null, so it tries to populate it, meaning it calls Pool.GetScoredEntries() again. Now imagine 50 threads come through. See the problem?
So we needed a way to signal that Pool.GetScoredEntries() was already running, so no other code would run it. As it turns out, that's what the lock keyword is for. After implementing it, this is what our updated code would look like:
1: private static object _cacheLock = new object();
2:
3: public List<ScoredEntry> GetScoredEntries()
4: {
5: List<ScoredEntry> entries = HttpContext.Current.Cache["ScoredEntries"] as List<ScoredEntry>;
6: if(entries == null)
7: {
8: lock(_cacheLock)
9: {
10: entries = HttpContext.Current.Cache["ScoredEntries"] as List<ScoredEntry>;
11: if(entries == null)
12: {
13: entries = Pool.GetScoredEntries();
14: HttpContext.Current.Cache["ScoredEntries"] = entries;
15: }
16: }
17: }
18: return entries;
19: }
A couple of things to note. First, we have a private static object declared. Second, we lock that object if the cache is null. The check for null inside of the lock() is because you could have a situation where while the lock is being obtained in one thread, another thread could hit the if statement and have it be true. Then the first thread would gain the lock, populate the cache, and release the lock. Once the second thread obtained the lock, line 10 will actually return the correct results. No need to repopulate the cache - that's the situation we were in before!
Also, one last thing about this code. I introduced a local variable (entries) that wasn't there before. I probably should have that in the original as well, because there's a slight possibility that in the time that I check if the cache is null and then grab the value out of cache, the entries could have been thrown out of cache. By using a local variable, I ensure that if that happens, it doesn't affect me.
Now, this code isn't exactly what we have for Tourneytopia. I don't use magic strings, nor are my methods that simple to call. And we don't have just one cache lock object. Because scoring (and thus, cache) is by pool, I have a method that gets the correct object to lock, based on a key, which is in turn based on a pool. That actually has its own lock object:
1: private static object _cacheSetter = new object();
2: private static Dictionary<string, object> _cacheLockList = new Dictionary<string, object>();
3:
4: private object GetCacheLockObject(string key)
5: {
6: if(_cacheLockList.ContainsKey(key))
7: {
8: return _cacheLockList[key];
9: }
10: else
11: {
12: lock(_cacheSetter)
13: {
14: if(!_cacheLockList.ContainsKey(key))
15: {
16: _cacheLockList.Add(key, new object());
17: }
18: return _cacheLockList[key];
19: }
20: }
21: }
The _cacheSetter object is locked only long enough to create the necessary cache lock object, which is by key. Then in my cache retrieval methods, I lock on that object. If there's an object already there for that key, it's returned. Otherwise, the global lock object is locked and the new object is created and added to the dictionary for that key.
Now, the same lines of code can be run by multiple threads for different pools, and not lock each other out, which is what we want, because in reality, they're actually setting different caches. This makes my GetScoredEntries look a little different:
1: public List<ScoredEntry> GetScoredEntries(string key)
2: {
3: List<ScoredEntry> entries = HttpContext.Current.Cache[key] as List<ScoredEntry>;
4: if(entries == null)
5: {
6: lock(GetCacheLockObject(key)
7: {
8: entries = HttpContext.Current.Cache[key] as List<ScoredEntry>;
9: if(entries == null)
10: {
11: entries = Pool.GetScoredEntries();
12: HttpContext.Current.Cache[key] = entries;
13: }
14: }
15: }
16: return entries;
17: }
Instead of locking on just one global object, we call GetCacheLockObject to get the actual object to lock.
Lots of tweaks involve making code run faster, This particular one has nothing to do with optimizing the code - it's all about making the code smarter so there aren't multiple instances of the same code running at the same time.
Tags: Lock | Performance
Categories: Develomatic, Development, C#
Url Rewriting And Form Actions
posted on 06/11/08 at 08:00:00 pm by Joel Ross
I have been working on a site for the past couple of months, and as part of that, we wanted to make our URLs prettier and more "hackable" - users are easily able to figure out how to get to the info they want.
Well, we ran into an issue with that. The page we rewrite to has a form on it and when that form posts back, we get Viewstate validation errors. That's a problem! Basically, the form has the wrong URL in the action, and we needed to somehow change the form's action.
Not that I'm surprised, but ScottGu already knows the solution. Towards the end of his post is a section titled "Handling ASP.NET PostBacks with URL Rewriting" and he mentions the problem I was seeing. He even has the source control for the form control adapter that solved our problem. It's written in VB.NET, and I needed it in C#, so I ported it. Here's the port:
1: public class UrlRewriterFormWriter : HtmlTextWriter
2: {
3: public UrlRewriterFormWriter(HtmlTextWriter writer) : base (writer)
4: {
5: base.InnerWriter = writer.InnerWriter;
6: }
7:
8: public UrlRewriterFormWriter(System.IO.TextWriter writer) : base(writer)
9: {
10: base.InnerWriter = writer;
11: }
12:
13: public override void WriteAttribute(string name, string value, bool fEncode)
14: {
15: if (name == "action")
16: {
17: HttpContext Context;
18: Context = HttpContext.Current;
19:
20: if (Context.Items["ActionAlreadyWritten"] == null)
21: {
22: value = Context.Request.RawUrl;
23: Context.Items["ActionAlreadyWritten"] = true;
24: }
25: }
26: base.WriteAttribute(name, value, fEncode);
27: }
28: }
The code isn't that complicated. Basically it looks for attributes named "action". Once it finds one, it updates the action to be the RawUrl - the pre-rewritten Url. Then it ensures that it doesn't do anything else (the ActionAlreadyWritten part). That way, the post backs work, and the "pretty Url" stays in the browser's address bar.
To use this class, you just override Render:
1: protected override void Render(HtmlTextWriter writer)
2: {
3: base.Render(new UrlRewriterFormWriter(writer));
4: }
That's it! Now your Urls stay pretty, and it got rid of our nasty viewstate issues.
Tags: Url Rewriting | ViewState | ASP.NET
Categories: Development, C#