
Changing Code In A Running Application
posted on 09/03/09 at 11:53:32 pm by Joel Ross
As part of a new application I'm building, we wanted it to work together with an existing application already in place - in fact, we wanted it to share the bulk of the implementation for saving certain types of data. The main requirement we had was that it would always be up. It could live through upgrades of the main application, and, at the same time, recognize changes to the main application, and use that new functionality when the main app came back online.
We considered a few different approaches. One was a file based approach. We could drop the data in a file, and the main application would pick it up and process it. But we wanted an interactive process - when data comes in, our main application might have messages that needed to be sent back to the caller. At least part of the process needed to be synchronous. Web services was another option, but that didn't solve our "always up" requirement during upgrades.
Eventually, I had the idea of dynamically loading the parts of our application that we need. As long as we kept the interface from this new application into the main application simple and flexible, we could get away without having to change the new application (that often), and just load in new versions of the main application. So I set about proving out the concept. As it turns out, it's very do-able, once you piece the right things together.
One of the key pieces is to have a shared project that both the main application and the new application know about. It'll be where you put your contract that the two apps will agree on. I did it with an abstract class:
1: public abstract class BaseType : MarshalByRefObject
2: {
3: public abstract string WriteSomething();
4: }
Since this was just a dummy application, my naming is a bit unrealistic, but I'm sure we can get past that. Now, we inherit from that in our main application, and, well, write something:
1: public class DynamicLoadedType : BaseType
2: {
3: public override string WriteSomething()
4: {
5: return "Version 1 was called.";
6: }
7: }
Simple enough. Now let's look at the other side. First, a quick note about application domains in .NET. You can't load a DLL into the current App Domain and still be able to unload it. It doesn't work that way, and people a lot smarter than I am can explain it better than I could. The bottom line is that you have to load the DLL into its own App Domain, and rather than unloading just the DLL, you unload the whole App Domain. Also, since we'll be loading a type from another App Domain, we're essentially using remoting, which if you paid close attention, would be why our BaseType inherits from MarshalByRefObject.
So, we create an App Domain, load our DLL into it and grab the type we want:
1: var setup = new AppDomainSetup
2: {
3: ShadowCopyFiles = "true",
4: ApplicationBase = @"C:\Bins"
5: };
6: _domain = System.AppDomain.CreateDomain("MainAppDomain", null, setup);
7: _baseType = (BaseType)_domain
8: .CreateInstanceFromAndUnwrap(@"C:\Bins\AppDomain.Dynamic.dll",
9: "AppDomain.Dynamic.DynamicLoadedType");
There's a lot going on here, and some of it deserves some explanation. First, most samples you find ignore creating your own AppDomainSetup class. I created my own because I wanted to use Shadow Copy. I didn't want to have the DLL that I loaded be locked. Now, I can drop in a new DLL over the old one, have my application recognize that, and automatically reload it.
Once the type is loaded, calling a method on it is as simple as calling any other method:
1: Console.WriteLine(_baseType.WriteSomething());
Using a FileSystemWatcher, I can watch the DLL I loaded, and when the DLL is changed, I can unload the App Domain:
1: _baseType = null;
2: System.AppDomain.Unload(_domain);
3: _domain = null;
Then, I load a new App Domain with the new DLL, and I'm back to processing calls - the whole time able to respond to incoming requests, even if it is to tell the caller that I can't handle the request and to try again later.
To prove this all out, I created a simple application that loops every second and if the DLL is loaded, it calls WriteSomething(). If it's not loaded, it just says so.
1: while(true)
2: {
3: if(manager.IsLoaded)
4: {
5: Console.WriteLine(manager.BaseType.WriteSomething());
6: }
7: else
8: {
9: Console.WriteLine("No File Loaded!");
10: }
11: Thread.Sleep(1000);
12: }
Also, when the DLL is loaded or unloaded, a message is written as well.
I started the application, changed DynamicLoadedType.WriteSomething() to return "Version 2 was called.", and dropped the updated DLL into the folder. Here's what I saw:
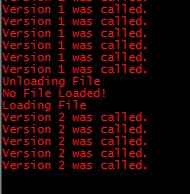
Without ever stopping the application, I was able to make code changes, drop them in a running application, and see those changes immediately. Not bad for an evening's work!
Categories: Development, C#
Unit Testing Has Changed How I Write Software
posted on 08/18/09 at 01:11:26 am by Joel Ross
A few months back, I remember having a conversation with someone about my views on test driven development and unit testing in general. I told him that, while I understood the benefits, I hadn't been able to see any of them. As a result, I didn't do a lot with unit tests, unless it was an obvious case that didn't have a major impact on the rest of the code base.
Of course, the reality is the other way around. I never saw the benefits of unit testing because I wasn't disciplined enough to write the tests, despite understanding the benefits.
Looking back, it was a poor decision on my part. Once I took the time (read: it's the way things are done at TrackAbout) to actually do it, suddenly those theoretical benefits became real. But more importantly, I saw what happens when you lack those benefits. Older parts of our system aren't completely under test, and frankly, changing those parts of the code is both dangerous and time consuming.
I didn't realize how much my development style had changed until I started a new project recently. In the past, my style was to develop vertical slices of the application, starting with a UI, and building down from there. Why? Because without a UI, I had no way to verify functionality. But this time, I started in the middle, with the main service of the application. Or, to be more to the point, I started with the tests for the main application service. When I ran into a need for something outside of the scope of what the service should do, I created an interface for it, mocked out the interface, and developed against that. Once done, I picked an interface I'd created and started working on that one. I worked my way through all of them, until I hit an edge, such as database access, web service calls, or third party components. By the time I was done, I had the core functionality of the system written and tested.
And I hadn't written a single line of UI code.
The UI was fairly simple, and was pretty quick to create. But the amazing part was that I only ran into a couple of bugs in getting the application up and running. And they weren't bugs in functionality - they were issues with how I wired my components together (using Ninject of course!). Once i got that functionality working, I was off and running.
It was a new feeling for me. I knew it would work because I had proof that it did work. And when I needed to change something, I had a designated place to start making those changes (it's test class), and could ensure that it didn't have far reaching effects on the rest of the system.
I still have a ways to go. I find myself just kind of flowing as I start to write code and suddenly realize I have a whole section that isn't tested, and I have to go back and write some tests to cover that. I still struggle with testing at the edge - where I'm finally to the point of writing the code that integrates with another component - be it a web service, an actual physical device or just a third party component. I find myself leaving that to test through in the application. I also haven't figured out the best way to test the UI or the Javascript I've been writing either. But, even then, it's easier to find the issues with them because I know the stuff under it is already tested and verified.
I know I'm late to the party on this, but I prefer to think of it as fashionably late.
Categories: ASP.NET
Acer Aspire EasyStore Home Server Review
posted on 06/25/09 at 11:07:33 pm by Joel Ross
Ever since Windows Home Server hit the streets, I've been eying them enviously. I looked at building my own, buying an OEM copy and repurposing a machine I had laying around the house (which was serving the same purpose, albeit all manually), and buying one of the HP models.
Ultimately, I delayed long enough for another option to be on the table: The Acer Aspire EasyStore Home Server. To me, there's two things I'm looking for in a home server: storage space and expandability. I don't really care about the extras that HP offers - the media capabilities and backing up Macs being the main ones. I'm pretty happy with my home network setup, other than my backup strategy.
Don't get me wrong. I had everything backed up - on a nightly basis. I used DeltaCopy on all of my machines, and scheduled it to run nightly. For my machines, I actively ensured that I'd selected accurate folders for backing up important data. For The Wife's laptop, I made sure that I backed up her important folders and told her where to put files to ensure they were backed up. I used Live Mesh to sync important files between machines and "The Cloud". And on a weekly (or so) basis, I used an external drive to do full backups of my main machines. Despite automating a lot of it, it was still a pretty manual process. I had to ensure I was backing up the right things, and if a drive did fail (luckily, it hasn't happened), I'd be stuck reloading the OS and programs manually.
Oh, and those weekly backups? Yeah, I might as well call them monthly.
Anyway, back to the home server. Acer (wisely, in my opinion) decided to keep it simple, and put out a home server without all the bells and whistles. It does what it says it will do (backup your machines reliably and simply), and does it at a great price - $399. So I got one. A few days later, it showed up on my doorstep.

For the record, that's a Steve Yzerman bobble head monitoring the unboxing in the upper left.

 I couldn't resist opening it, and it turns out it's a nice looking machine. All of my pictures of the outside were blurry, but frankly, that works since I'm more interested in the inside. Hot swappable drive bays (another advantage over building my own or repurposing an existing machine) are very nice!
I couldn't resist opening it, and it turns out it's a nice looking machine. All of my pictures of the outside were blurry, but frankly, that works since I'm more interested in the inside. Hot swappable drive bays (another advantage over building my own or repurposing an existing machine) are very nice!
Setting up all of my machines to backup was a breeze. With about an hour of work, I had all of my machines set up. I have 5 machines backing up regularly now. The initial backups took a while - I forced a few to start, and each machine took between 2 and 5 hours, depending on how much data and its network connection (the slowest was our older desktop, which has about 100 GB of data and is connected via a wireless connection). Now that they're all backed up, the nightly backups are relatively quick. I set backups to run between midnight and 7:00 AM, and they usually finish before 3:00 AM. One other nice thing is the home server is capable of waking up machines to back them up. I'm able to set my machines to sleep or hibernate after an hour of inactivity, and safely rely on them waking up to get backed up. Before, I had to leave them on at night, so they'd get backed up (or schedule them to be backed up during "busy hours").
So far, I haven't done too much with it, other than using it as a backup server. I have loaded some videos on it, and can watch them on my Xbox 360 (who needs the media capabilities of the HPs anyway!). I installed PlayOn Server on it as well, so I can play Hulu videos on my 360 as well. Getting PlayOn installed is pretty simple, but requires installing Window Media Player 11 on the server first.
As I mentioned on Twitter, I've added my WHS box to Live Mesh, which required jumping through a couple of hoops, but nothing too major. And the end result was worth it - I now pull down mesh data into my personal share, which then gets duplicated on there - that means that any data I add to Mesh is in at least 4 places: The machine it was added on, the cloud, and on the home server - twice!
About the only other thing I've done is hook it to a UPS. I have the APC Back-UPS ES 550VA, and while it's not huge, the only thing I want is for the server to shut down properly if the power goes out. One note here: do not use the built-in software that comes with the UPS. Everything I read says it can result in data corruption. Luckily, there's Grid Junction, a nice, free add-in that can be used. It's simple to install and it picked up my UPS without issue.
I did get an extra drive to go in the server, so I have 2 TB of backup space to work with. With having 5 machines to back up, I honestly wasn't sure how much space I would need. If I look at my disk usage and just add it up, it's about a terabyte of space. After running daily backups for a little over a week, I've used about 400 GB. I'd heard it was pretty smart about how to avoid duplication, and I'm sure there's some compression going on, but that's pretty impressive. Since I have two drive, I also enabled folder duplication for all of my shared folders. There's a chance those shares could be the only place a file is located, so having it backed while on the server is just as important as if it's on my machine, right?
I really can't think of anything bad to say about the machine. It works as advertised, it's small, and it's quiet. If you're looking for a solid machine to manage backups, I would highly recommend it.
Categories: General
What’s this? Ads In My Feed?
posted on 04/29/09 at 11:52:59 pm by Joel Ross
For those who read RossCode.com by visiting the site, this post won't mean much to you. For those who subscribe to the feed, you may have noticed a new item in the feed: An advertisement. And that's a big change for me.
About a week ago, I joined the RSS Room of The Lounge. It was not a decision I took lightly. My view on advertising has always been to make money on casual visitors (mostly from Google searches), but not to make money off of the dedicated readers of my blog - the ones who subscribe to the feed.
So putting an ad in my feed is a bit hypocritical then, right? Well, not exactly, and let me explain why. Until joining The Lounge, the ads on my site were never really relevant. Yeah, Google thought they were relevant, but I never looked at the ads and thought, "I'd use that." That's not the case with the ads on my site now. I look at the companies advertising here and realize that I use their software, and I feel like they actually add value now. So putting ads in my feed no longer feels like I am just making money off my readers. Your opinion may differ, and if it's a real problem for you, please let me know why. I'd love to get feedback.
Oh, and while we're at it, The Lounge is conducting a survey to get feedback on who their target audience is. You'll also have a chance to win all 41 of the Manning In Action books, so please take a moment to fill it out. I did, and it doesn't take more than a few minutes.
Categories: Blogging
Data Synchronization and the Compact Framework
posted on 04/27/09 at 12:13:58 am by Joel Ross
Over the past few weeks, I've had a chance to really dig into certain parts of the Compact Framework. We're taking on a major mobile development project, and one of the key parts will be how we move data from the website to the device and back.
So far, we've looked at a few different options, and I've come up with a few plusses and minuses for each. I figured I'd share that information, and see if anyone knew of other options and/or other benefits of the methods I'll mention.
One thing that I feel I should mention: In our current situation, we don't envision the need to have true data synchronization capabilities. We have a handful of reference tables that come down from the server. On the device, we create new entries (in another table), and send those back to the server. Any changes to the data on the client would be thrown away on the next sync with the server. That affects my view of the options, because collision detection and resolution might be stronger in one versus the other.
Sql Server Replication
I've typically heard replication used in terms of server to server communication, but it can also be used to move data from a server to a client, and synchronize changes back to the server. You can specify what tables (and columns) you want sent to the client, and you can limit the data sent to the client based on a few parameters sent by the client.
The most compelling argument for using replication is schema management. Any changes you make at the server level to the publication are automatically reflected in the client's database. Not having to worry about a database migration strategy for our devices sounds very appealing. Oh, and it doesn't hurt that it's extremely efficient at replicating the data. In an admittedly unscientific test, we saw replication from a server take less time than running through a series of inserts where the data was already loaded in the device's memory. That's impressive!
But, unless we're missing something, because of the immediate nature of schema change replication, we'd most likely have to miss out on the benefits it provides. We don't roll out new versions of our mobile application all at the same time, or at the same time we roll out web updates. Having the server publication change for everyone could be troublesome, so we'd likely be maintaining a publication per version of our software. Not horrible, but ideal.
There's a few other things I didn't like about this solution either: It's seems like the client needs to know a bit too much about the server - basically, enough info to create the server's connection string. I guess this is logical, because the server doesn't have to know about clients ahead of time, but with the possibility of devices getting lost or stolen, this seems risky. One more downside. Every table gets modified to add tracking information to the table for changes. Not a huge issue, but depending on what sync options you specify, the client database seems to grow beyond what I would have expected.
The setup is a bit touchy as well. Once you have it working, it's fine, and a lot of the problems I ran into were probably one time things or a lack on knowledge. Still, it seemed like it could be a whole lot cleaner.
Remote Data Access
Remote Data Access (RDA) has three different options for moving data between the server and the client: Push, Pull and SubmitSQL. Pull gets data from the server and puts it on the client. Push is a way to get data from a pulled table back to the server, which means we didn't look at it that closely. SubmitSQL is a way to create new records on the server with data from the client.
If we accept that we basically lose schema management with replication because of our requirements, then RDA seems a much simpler solution. We now have full use of SQL stored procedures, UDFs, etc., to help with how we select data, and we can pass back multiple identifiers from the client.
The downsides are roughly the same as replication - too much server side knowledge by the client. I understand why, but that doesn't mean I'm comfortable with it! Schema management is also a bit tougher - essentially, a table that's managed via Pull is not allowed to change. It's not horrible though - you can just drop the table with a new build, and have it re-added on first sync. Again, not ideal, but it works.
Unlike replication, setup for this is a breeze - no SQL server steps involved, and minimal IIS work (in fact, once replication was set up, there were no extra steps involved).
Oh yeah. One more downside for RDA: It's going to be removed from future versions.
Microsoft Sync Framework
But Microsoft never removes something without adding something similar, right? For the most part, yes, and in this case, there is an alternative as well: Synchronization Services. We've just started digging into this one, since I originally read it only supports Windows Mobile 5 & 6, where as we require CE support as well.
The upside is high for this one. We can use an alternate database on the device if we want - it supports any database that supports ADO.NET. That's nice, because we've contemplated looking into Sqlite as our store, since in our initial testing, it's quite a bit faster than Sql CE.
The downsides here are roughly the same as RDA, which isn't surprising given it's meant as the replacement for RDA - we have to manage schema changes ourselves. Oh, and the documentation and samples leave something to be desired.
Roll Our Own
What can I say? I've yet to see a wheel where I haven't thought, "I could re-invent that!" Ok, that's not true. I'd much rather find something that does what I want so I can focus on other problems. But there are times where you can't find a solution that fits your needs well enough to actually be called a solution. If the above solutions don't end up fitting our needs, we always have the option of hand crafting a solution that does.
The upsides to this are obvious. We'd get to choose exactly how we do everything. We can solve all of the downsides of the above solutions, and avoid all of the negatives. All of the above solution
The downsides are also obvious. We have to do it all. We have to maintain it. There's no new version coming that has a killer feature (unless we add it ourselves). It increases the timeline, because we're doing the work, and we're not benefiting from other's experiences.
After writing this, I found this chart to be helpful to review and verify what I said. It's a comparison between the different sync options (minus roll your own).
I don't think we've landed on a solution yet, so I'm seeking feedback. Are there other reasons to go with one of the above solutions (or not to!)? Am I missing a solution? What solutions have you used in the past? Would you go the same way if you had to do it again?
Tags: CF.NET | Sql Server | Replication | Synchronization
Categories: ASP.NET
2nd Annual RossCode.com March Madness Pool Contest
posted on 03/16/09 at 08:55:40 pm by Joel Ross
Last year, I decided to actually step back and enjoy myself during the March Madness tournament and host my own pool. Well, I'm doing that again this year, and I'm inviting readers of my blog (that's you!) and my Twitter followers to join. And anyone else I can think to invite.
There's no prize - just the pride of knowing that you picked the teams better than any of the other geeks! Maybe you can unseat last year's winner - Erik Lane. After you enter my pool, you'll be shown the option to add your pick to the main pool - where there is a prize - a $25 Best Buy gift card.
Oh yeah. If you're reading this and thinking, "There's no point in me entering. I don't know anything about basketball." - it doesn't matter. I've heard countless stories of people who won a pool by picking teams by uniform colors! Or there's a former colleague, who apparently picks based on mascot dominance and seismic zones! So don't let lack of knowledge hold you back. Submit your picks now!
Categories: Development, Just For Fun
Tourneytopia 2009
posted on 03/12/09 at 08:32:48 pm by Joel Ross
For Develomatic, the first quarter of the year is by far our busiest time. We usually add a few features to Tourneytopia that our users have asked for over the past year, as well as having more sales and support calls than any other time of the year. With Selection Sunday just a few days away, this year is no exception.
Just this past week, we wrapped up the final touches, fixing the few minor issues found during the Accenture Match Play contest - a contest that we originally started using as a way to beta test the site in anticipation of March Madness. Now that we run numerous tennis tournaments throughout the year, it's no longer as useful to use it that way, but we still use that as a target for feature completion for the NCAA tournament.
So what did we spend our time doing this year? Well, let's see:
- Updated the look and feel for the pools. Before, we had to rely on Javascript to finalize the layout to get it to work right, but we re-did it a bit, and I think it works better now than before.
- Added custom skins. Last year, we simplified our styles in such a way that we could easily add skins to the site, and we added about 10 for people to choose from. This year, we took it one step further, and we allow you to choose any custom colors combos!
- Pool Admins can now submit picks after the deadline. This is one feature that we resisted adding, but finally decided it was time. Now, if you're running a pool, you can add picks after the window closes. This'll let admins add picks for people who turn in paper brackets. Except they all go under the admin account...
- ...which brings me to the next new feature: transferring picks to other users. In the above example, after the admin submits a pick, they can go to their account page, click a button, and get a URL that they can send to someone. When they click on that link, the pick will be transferred to their account. This was probably the second most requested feature, right behind admins being able to submit after the deadline.
- Integration with PayItSquare.com. We've been running these two services for a couple of years now, but we'd never put them together. This year, after getting no requests like this in the past, we got several inquiries about collecting entry fees - specifically for charity pools. One person said integration between the two would be a selling point for us over other pool management software. So we added it.
We've done a few other thing as well to improve performance - but those aren't really features. But know that we've had our eyes on performance, and made several software tweaks as well as hardware changes to ensure that the site performs up to our standards.
With the tournament just days (hours!) away, I can't wait!
Categories: Development
Develomatic Featured As Startup of the Day
posted on 03/02/09 at 10:55:16 pm by Joel Ross
 If you follow me on twitter, you may have picked up a few months ago that Develomatic had joined the BizSpark program. It's a great opportunity for us to get help to us grow our business through free software and support from Microsoft.
If you follow me on twitter, you may have picked up a few months ago that Develomatic had joined the BizSpark program. It's a great opportunity for us to get help to us grow our business through free software and support from Microsoft.
What we didn't count on is the visibility we might get from the program. Today, that changed, as we're being highlighted as the Startup of the Day on the Microsoft Startup Zone web site. There's even a nice interview with Brian, my partner. Go check it out!
Categories: Develomatic
5th Annual Accenture Match Play Contest
posted on 02/23/09 at 07:57:02 pm by Joel Ross
That's right. For the 5th year in a row, Develomatic is running a contest to see who can make the best picks for the Accenture Match Play tournament that starts this Wednesday. As is custom, we're giving away a $25 Best Buy gift card, so if you're interested, head on over and submit a pick.
We've added a bunch of new features this year and a new look. I'll go into more details on the new stuff later, but for now, you've got until Wednesday morning to get your picks in!
And as always, if you have any feedback on the site, please let me know.
Tags: Golf | Tourneytopia | Accenture | Match Play
Categories: Develomatic, Just For Fun
User Defined Functions and NHibernate
posted on 02/22/09 at 10:11:00 pm by Joel Ross
At TrackAbout, where I've been working for a few months now, our database has a lot of user defined functions in it. This past week, one of my tasks involved using one of these functions in conjunction with an NHibernate object.
There's a couple of ways it will work - CreateSqlQuery and CreateQuery come to mind, but I also had another requirement: Eager load a few collections. This was part of an export that includes a lot of related data, so it was important to load it all at once. The best way I could figure out eager loading was with Criteria, so I went with that that. There's probably a better way, but I'm still fumbling my way through and learning NHbernate. In fact, over the weekend, I just got my copy of NHibernate In Action.
Anyway, searching around, I found a few examples of using scalar functions, but not much on functions that return a table, which is what I was dealing with. After seeing a few hints here and there, I finally pieced together what worked for me. I've "Northwind-ized" the classes, but the gist is the same.
1: return _session.CreateCriteria(typeof(Customer))
2: .Add(Expression.Sql("{alias}.Id in (select Item from dbo.ParseCsv(?))", custIdList, NHibernateUtil.String))
3: .SetFetchMode("Orders", FetchMode.Eager)
4: .SetFetchMode("Products", FetchMode.Eager)
5: .List<Customer>();
custIdList is a list of customer Ids coming from customer checkboxes checked on the screen. The function takes the list of customer ids and inserts them into a table, which you can then use in your queries. I tried using Exression.In, but realized that there's a limit in SQL Server of 2,100 input parameters. My particular test case happened to have 9,300 customers, so I stuck with the SQL function.
I should note that this is written against NHibernate 1.2, which is what we use right now. I'm too lazy...err...I'll leave it as an exercise for the reader to figure out if it's the same in 2.x.
Categories: Develomatic, C#