
Code Smell: Switch Statements
posted on 11/01/07 at 09:37:54 pm by Joel Ross
I've never really thought too much about switch statements as being a sign of code smell, but after reading Jeremy Jarrell's post about refactoring switch statements with the Strategy Pattern (the Wikipedia entry has C# code in it!), I'm starting to see the light. That, and I'm working with some code I wrote a few years ago, where I have the same switch statement (or in some cases, the same set of if / else if / else statements) over and over.
Jeremy says the main reason to do this is in case you end up adding new values to the switch statement down the line, but as I started looking at what he was writing and what I was seeing, I think I can benefit from it even though I know there won't ever be another value in these switch statements. I know - I shouldn't say "ever" but in this case, I'm very sure there won't be. There hasn't been a new value since the original three were added, and the vertical business isn't changing in that way.
Want an example where the values won't change? Primary colors: Red, Green and Blue. So let's use those as an example. You have three operations that need to occur. OperationOne is color specific. OperationTwo is generic, but relies on OperationOne already running. OperationThree is also color specific, and relies on OperationTwo completing. Using switch statements, it would look something like this:
1: public void DoColorWork(ColorObject color, ColorManager manager)
2: {
3: switch(color.PrimaryColor)
4: {
5: case PrimaryColor.Red:
6: manager.OperationOneRed(color);
7: break;
8:
9: case PrimaryColor.Green:
10: manager.OperationOneGreen(color);
11: break;
12:
13: case PrimaryColor.Blue:
14: manager.OperationOneBlue(color);
15: break;
16: }
17:
18: manager.OperationTwo(color);
19:
20: switch(color.PrimaryColor)
21: {
22: case PrimaryColor.Red:
23: manager.OperationThreeRed(color);
24: break;
25:
26: case PrimaryColor.Green:
27: manager.OperationThreeGreen(color);
28: break;
29:
30: case PrimaryColor.Blue:
31: manager.OperationThreeBlue(color);
32: break;
33: }
34: }
It's not horrible, but it can definitely be done better. Using the strategy pattern (and the Factory pattern), this can be done cleaner:
1: public void DoColorWork(ColorObject color)
2: {
3: ColorManager manager = GetColorManager(color);
4: manager.OperationOne(color);
5: manager.OperationTwo(color);
6: manager.OperationThree(color);
7: }
In the above, I use a factory method (GetColorManager) to return an instance of ColorManager.
1: public ColorManager GetColorManager(ColorObject color)
2: {
3: switch(color.PrimaryColor)
4: {
5: case PrimaryColor.Red:
6: return new RedColorManager();
7:
8: case PrimaryColor.Green:
9: return new GreenColorManager();
10:
11: case PrimaryColor.Blue:
12: return new BlueColorManager();
13: }
14: }
The ColorManager would be virtual and define OperationOne, and OperationThree to be abstract, while providing the implementation for OperationTwo. Each concrete class (RedColorManager, GreenColorManager, and BlueColorManager) would implement OperationOne and OperationThree with color specific code.
In the example, I still have a switch statement, but I'm down to just one, and that code 1.) is easier to maintain the way it is, and 2.) could be refactored further. Since it's only in one place, it wouldn't be a huge deal to leave it as a switch statement, and as long as the functionality is the same, refactoring can be done later if needed.
Of course, you could argue that going from two switch statements to one isn't a huge savings. That's true. But in some code I'm working with, I could have a Manager factory that I get once, and I could literally change 50 or more switch statements throughout the application. Now that would actually be worth it!
Categories: Development, C#
07-08 Week 9 NFL Picks
posted on 11/01/07 at 12:16:08 am by Joel Ross
After this week, we'll finally get a feeling for just how good New England is. Yes, they're good, but their opponent's record is a combined 24-34. Not exactly stellar. Their biggest win has come against Dallas, the cream of the crop in the NFC, but this year, there seems to be a big difference between the NFC and AFC - the AFC is far superior. The (pretty much) unanimous picks for the top two teams in the league are New England and Indianapolis, with whoever that third team is being a distant third - either Dallas or Green Bay, depending on who you're talking to. And remember, New England dropped Dallas by 21 points in week 6. If they can put those kinds of numbers up against Indy, then they deserve to be where they are. My guess is that Indy will be ready, and we should have a great game on Sunday.
- Washington vs. New York Jets (-4) (35.5 O/U)
- Carolina vs. Tennessee (-4) (35.5 O/U)
- Jacksonville vs. New Orleans (-3) (40 O/U)
- Arizona vs. Tampa Bay (-3.5) (37.5 O/U)
- Denver vs. Detroit (-2.5) (46 O/U)
- San Diego (-7.5) vs. Minnesota (41 O/U)
- San Francisco vs. Atlanta (-3) (37 O/U)
- Cincinnati (-1.5) vs. Buffalo (43 O/U)
- Green Bay vs. Kansas City (-2) (37 O/U)
- Seattle vs. Cleveland (-1.5) (46.5 O/U)
- Houston vs. Oakland (-3) (41.5 O/U)
- New England (-5) vs. Indianapolis (56.5 O/U)
- Dallas (-3) vs. Philadelphia (46.5 O/U)
- Baltimore* vs. Pittsburgh (-9) (36 O/U)
For my "Lock Solid" picks this week, I'm going with Tennessee (-210), San Diego (-335), Cincinnati (-120) and Pittsburgh (-430).
Check back next week for my results.
Categories: Football
Datasets Vs. Custom Objects
posted on 10/31/07 at 10:56:52 pm by Joel Ross
A few days ago, we got a question in the discussions for the NuSoft Framework asking, "Why not just use a strongly-typed DataSet?" Honestly, I was a little taken aback by the question. I haven't used datasets or typed datasets in probably 4 or 5 years, so I guess I wasn't even aware that some people were still choosing datasets.
My views on Datasets
Having used typed datasets a little bit in the past, my experience was that they gave you a lot of good functionality. It's easy to create them and it does a good job of extracting the database interaction away from the developer, but there were still a few issues that left me searching for a better solution:
- Adding functionality: While using datasets, you get a lot of functionality created for you. It gets you 80% of the way there, but adding that last 20% can be painful and the code is difficult to maintain.
- Database changes: I have yet to work on a project where the database didn't go under changes throughout the project. As we've done more and more agile projects, the database changes are much more frequent as we add new pieces of functionality. Having to recreate the typed datasets becomes a pain.
- Programming interface: While there are probably a few tools that can alleviate the above problems, I never spent time looking for them because I'm not exactly thrilled with the interface provided - it's not how I want to develop software. When I'm writing code against a dataset, I feel like I'm spending more time working (or fighting) with the technology of datasets than I am working with my domain.
Enter CodeSmith and Code Generation
Because of the above issues, I started using hand-written custom objects. This was back in the .NET 1.x days, so the first thing to figure out was how to have a typed collection. Because they're such a pain to create manually, I turned to CodeSmith because it's collection generators were well regarded.
Once I was used to CodeSmith's syntax, I started to realize the power it has when connected to a data model. I quickly realized that most of my business objects look similar - the differences were in properties and the "guts" of the CRUD methods - and the differences correlated directly to the differences in the tables that held that data. Since CodeSmith can get at a lot of the metadata in a database table, it was simple to create a quick custom object template that I could use to get started. From my above issues with datasets, this solved two of them. I was able to define my own interface, so it was exactly what I wanted to develop against, and adding functionality it easy - It's a standard class, so I'd just add new methods. It wasn't until later that I figured out how to deal with the last issue. Once I moved most of my development to .NET 2.0, I was able to do what I wanted by generating partial classes.
The NuSoft Framework was born
Around that same time, there was a push at NuSoft to standardize our development efforts - a few of us had been leading projects and doing things pretty much the same, but slightly different. We got together and worked out our differences, and the end result was a set of CodeSmith templates that we could use for our projects. The code was familiar to all of us, and we could easily extend it while still being able to re-generate whenever we needed to change the database.
About a year after using the NuSoft Framework internally and tweaking it, we released it as an open source project on CodePlex. Since then, it's evolved a bit and we are still actively using it internally. On the projects I've used it on, it solves all three of the issues with datasets: It's easy to add functionality, I can re-generate at any time without losing changes, and when writing code against it, I feel like I am working with my domain and not with the technology.
What others are saying
When I got the original question (way back before I started rambling!), I hit up "my peeps" to see what their opinion was - using Twitter, of course! I didn't get a ton of replies, but I got a couple. The first was from Scott Coon, but the link he provided doesn't seem to work anymore. I searched around, and I think he was referring to a couple of posts that are mainly focused on performance differences between the two.
The other response was from Keith Elder, who didn't really answer, but he did put up a full fledged blog post about it. If you read through it, "The Elder" makes a strong argument for plain datasets. But when expanding his scenario a bit, he starts to lean back towards custom objects:
Maintaining customer information in just a Dataset scenario is slow, lots of overhead and isn't near as clean as just a plain old C# object (or entity, however you think of it). We can wrap our Customer entity with policy injection and validation much cleaner than we can trying to represent a Customer in a DataSet no matter how we look at it.
Basically, he favors datasets for simple scenarios because of their ease of development and not needing to write custom code for things such as filtering and sorting. My issue with that is that by using a solid framework, that code can be created automatically. Sorting is built into the NuSoft Framework, and filtering isn't built in, but could be done in just a few lines of code using pieces that are generated. He does, however, make a very valid point when talking about displaying a list of just a few of the properties, since most object frameworks populate full objects.
To be honest, looking into this whole thing, I was surprised that people still use datasets at all. I remember the argument back in .NET 1.0, and you saw a lot of code samples from Microsoft utilizing them, but more and more sample code used custom objects starting with .NET 1.1, and you rarely see any datasets with 2.0 code. And yes, I realize that code samples shouldn't be a measure of what people are (or should) be doing, but given the tendency of developers to take samples and turn them into production-ready code, it does give a little insight into how people are building software.
Anyway, as Keith says, it's all "clear as mud" now!
Tags: Datasets | Custom Objects
Categories: Development, C#
I Can Finally See How Valuable BlogRush Is!
posted on 10/31/07 at 08:30:34 pm by Joel Ross
So after signing up for BlogRush over a month ago, they rolled out a new dashboard and reports. I can finally get some insight into what I've gotten out of it. I can finally see some reports, and I have an idea of exactly how many visitors I've received by having the widget on every page of my site:
0.
Yup, that's right. Not one single visitor:
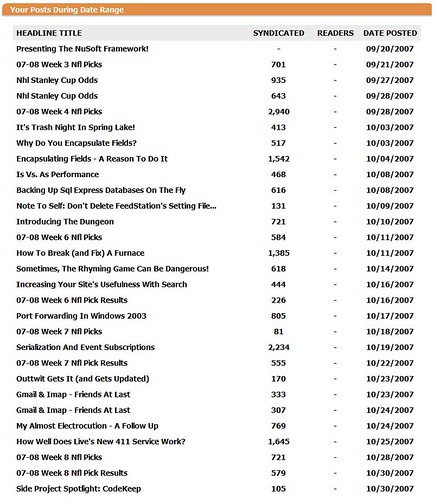
All of those dashes under "READERS"? That means no traffic has come from being in the BlogRush network. The next step for me is to figure out why this is. There's really two possibilities:
- BlogRush doesn't really drive the traffic they promise.
- My headlines aren't catchy enough.
My guess is that it's a combo of the two. I'm not really good at flashy headlines, and don't always think of it anyway when I'm writing a post. Most of the time, I write the headline first, and then quickly move on to writing the post. In reality, I should write the post first and then write the headline afterwards. So, from that standpoint, I can't place all of the blame on BlogRush.
Now from BlogRush's side. Even their own demo video shows a click through percentage of .17% to .07%. I'm sure their answer would be referrals - you can refer people and when they sign up, you get credits for their impressions as well as your own. Your referrals can go 10 levels deep, so if you built a nice pyramid under you, you could generate quite a few credits and get a lot of headlines. But there's two issues with signing up referrals.
First, you have to have something compelling enough to keep people signed up. A lot of people will try something, but they need to see some return quickly or they're going to bail. When I was younger, a few of my friends got into selling long distance. This was back when long distance was still pretty expensive, and virtually no one was offering unlimited pricing. The price they offered was compelling, and people signed up. But they didn't stick around long enough for my friends to make any money. It's the same thing here, except with credits for impressions. People have to stick around, and for them to do that, you have to be the best option out there.
Second, I have to a compelling reason to want to sign up others. I have a few friends who blog, who, if this drove actual, real traffic, would be willing to sign up. But how can I justify wanting to sign others up? I've had over 4,000 impressions, had a widget on my blog for a month and a half, and have gotten exactly nothing in return.
I've removed the widget. I'm looking for something to put in it's place - that either earns money or drives traffic to the site. Any ideas?
Update: While sitting on this post, I noticed at least one other blogger seeing the same thing.
Categories: Blogging, Software
URL Rewriting And Links In Your ASPX Pages
posted on 10/30/07 at 10:17:40 pm by Joel Ross
Last night, I was adding a new feature to Tourneytopia to allow in-place editing of content. Once published, you'll be able to pop a modal dialog with a text editor in it, update the content, click update, and see it updated on the page immediately.
But when I got it developed and started to test it, I got a 500 server code returned to me. Removing the UpdatePanel, I was able to see the real issue. It said it couldn't find the supporting files it needed. Looking at the editor in the ASPX page, we have this line:
<ftb:FreeTextBox id="editor" runat="server" Width="600px" height="400px" SupportFolder="~/FreeTextBox.axd" />
The problem, as it turns out, is that last attribute. That, combined with the fact that we use URL rewriting for all of our pool pages for the site. I've run into this in the past, but with images. Anytime an image has it's URL specified in the page, URL rewriting will cause a problem. Basically, when you specify the URL in the ASPX part of the page, it will create an path that doesn't take into account the rewritten path - the one the browser will use to resolve paths to the images.
To solve the issue, you simply set the property in the code behind, and all is well:
protected void Page_Load(object sender, EventArgs e)
{
editor.SupportFolder = "~/FreeTextBox.axd";
}
By setting it in the code behind, the path will be set properly. Once I did this and added the UpdatePanel back in, my editor worked, and we now have a much better content management experience for March.
Categories: Develomatic, Development, C#
Side Project Spotlight: CodeKeep
posted on 10/30/07 at 09:37:11 pm by Joel Ross
James Avery has an interesting idea: interview people about their side projects and their motivations and goals for working on it. His first one is with Dave Donaldson about CodeKeep, a cool Visual Studio add-in that allows you to share code snippets. The interview is short, but gives you a good idea of what CodeKeep is and some upcoming news about it.
What's next for CodeKeep?
I’ve got some new functionality I want to release, but the biggest thing will be making the CodeKeep add-in an open source project. I haven’t worked out all the details for that yet, but it’ll be soon. My hope is that the community can take the add-in to a level it won’t otherwise go if left only in my hands.
He goes on to say that he hopes the community adds the idea of groups, something that I asked him about when I was helping him test it way back when.
Anyway, I'm looking forward to seeing more of this series from James. It's interesting to see what others are doing with their spare time. I personally think it's a sign of a good developer that they are working on a side project of some sort.
Categories: Blogging, Software
How I Consolidated My Many Email Addresses
posted on 10/30/07 at 08:39:07 pm by Joel Ross
The Problem
With the recent announcement that Gmail would support IMAP, I've started to rethink how I handle email. It's not that I had a major issue with the way I was reading my email, but at certain times, it was a pain.
- Remote Email: Any time I am away from my laptop, reading email is a pain. There's two different ways I read email when I'm away: on my Axim (Pocket PC) or on another computer. I had all of my accounts set up on my Axim using POP access. The problem is that most of the time when I am away from my laptop, it's usually on anyway, with Outlook running, so it's pulling down my email every 30 minutes. That means that if I check my accounts remotely, at most I have email from the last 30 minutes available. I could set it to leave mail on the server, but that has always led to issues in the past when the account gets filled up. Gmail doesn't have this problem, and I know you can use recent as part of your email address to allow messages to be retrieved on multiple devices, but this all leads into another issue.
- Synchronizing Read Statuses: If I read a message from anywhere other than my laptop, my laptop doesn't know that. If my laptop pulls the message down, then it's marked as read automatically. That means if I go onto my Gmail account online, the message has been marked as read already. I can usually tell what I've actually read and what I haven't but it's not ideal.
- Too Many Accounts: I regularly check six personal email accounts. I have reasons for each, but it's a pain if I'm away - six places to go to find online email. For the most part, I didn't even bother, partly because I didn't want to check six different places, and partly for the reasons listed above. It's also a pain to set up whenever I have to set them up on my laptop. Remembering all of the different setups is difficult, and usually takes a while to complete.
The Requirements
In many different ways, I've been trying to streamline my life. Email was one of those things I wanted to take a look at, so last night, I started the process. I had a few goals in my transition.
- Funnel all incoming email into one email account.
- Allow email to be managed and stored online.
- Allow "thick client" access to email, while still allowing the online service to manage the email.
The Solution
I mainly use my RossCode.com email address, so that's where I wanted to funnel the email to. For three of my email accounts, it was just a matter of going into the account and setting up forwarding to my main address. Since I am the only person who uses email on the RossCode.com domain, I used separate addresses for each account - for example, I forwarded my Gmail.com address to gmail [at] rosscode [dot] com. This allows me to use Outlook to filter emails if I decide to do so in the future. For my other accounts, I set up POP access to those accounts in Gmail. Gmail allows you to set up accounts that it will grab email from, so that's what I did. By the time I was done, all of my email flowed through my RossCode.com email.
Having it all go through Gmail satisfies the second requirement, and having IMAP access to that account satisfies the last one. I can now read email on my laptop and have it all reflected online. I can have the same IMAP access on my Axim as well. And if I'm away from both of those, I can go to my online account and read email that way - and it all gets updated on my laptop and Axim. The perfect email world!
Lastly, I was curious how Gmail would handle creating folders in an IMAP account. Remember, Gmail doesn't have the idea of folders. It uses labels and stars. When you connect to Gmail for the first time, you get a [Gmail] folder with the views that Gmail provides underneath it. Here's my IMAP account in Outlook:
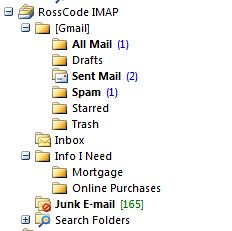
Notice I've created a few folders, such as one called "Info I Need" with two folders underneath it. In Gmail, those are treated as labels:
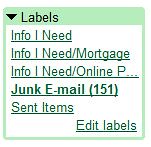
That's a pretty good implementation - Google's done a good job of translating from their no folder model that Gmail introduced to a traditional folder model.
Now that this is all set up, I'm able to read email on my laptop, Axim and online and have it all be updated on my other devices - and any device I add down the line that supports IMAP.
Tags: Email | Gmail | Google Apps
Categories: Personal, Software
07-08 Week 8 NFL Pick Results
posted on 10/30/07 at 12:34:43 am by Joel Ross
Not a bad Sunday for me. My O/U picks were solid, as were my picks. I ended up $32 for the week. That's two weeks in a row of $30 or more in winnings.
I also did good on my "Lock Solid" picks this week. I went 4-0, winning $16.73 on $40 in bets. That's a decent one day return! Unfortunately, for the season, I'm still down $9.27, despite being 23-9.
- Indianapolis 31 (-6), Carolina 7 (44.5 O/U) [P: $3.70, S: $10.00, O/U: ($10.00), T: $3.70]
- Pittsburgh 24 (-3), Cincinnati 13 (48 O/U) [P: ($10.00), S: ($10.00), O/U: $9.09, T: ($10.91)]
- Oakland 9, Tennessee 13 (-7) (40.5 O/U) [P: $3.33, S: ($10.00), O/U: ($10.00), T: ($16.67)]
- New York Giants 13 (-9.5), Miami 10 (48 O/U) [P: $2.15, S: ($10.00), O/U: $9.09, T: $1.24]
- Cleveland 27 (-3), St. Louis 20 (45 O/U) [P: $6.06, S: $10.00, O/U: ($10.00), T: $6.06]
- Detroit 16, Chicago 7 (-5) (45 O/U) [P: ($10.00), S: ($10.00), O/U: $9.09, T: ($10.91)]: Chicago loses to Detroit twice. 50 yards rushing for Cedric Benson? Think they regret letting Thomas Jones go?
- Philadelphia 23 (-1.5), Minnesota 16 (37.5 O/U) [P: $7.69, S: $10.00, O/U: $9.09, T: $26.78]
- Houston* 10, San Diego 35 (-11.5) (45 O/U) [P: $2.00, S: ($10.00), O/U: $0.00, T: ($8.00)]
- Buffalo 13, New York Jets 3 (-3) (37.5 O/U) [P: ($10.00), S: ($10.00), O/U: ($10.00), T: ($30.00)]
- Jacksonville 24, Tampa Bay 23 (-3.5) (32 O/U) [P: $17.00, S: $10.00, O/U: $9.09, T: $36.09]
- Washington 7, New England 52 (-16.5) (48 O/U) [P: $0.63, S: $10.00, O/U: $9.09, T: $19.72]: Another run up by New England. It'll be interesting to see if they can run it up against the Colts.
- New Orleans 31 (-2.5), San Francisco 10 (40 O/U) [P: $6.90, S: $10.00, O/U: $9.09, T: $25.99]
- Green Bay 19, Denver 13 (-3) (42 O/U) [P: ($10.00), S: ($10.00), O/U: $9.09, T: ($10.91)]
Results Summary
- Picks (this week): 9 - 4 (69.23%) - Winnings: $9.46
- Picks (season): 74 - 42 (63.79%) - Winnings: ($63.79)
- Spread (this week): 6 - 7 (46.15%) - Winnings: ($10.00)
- Spread (season): 49 - 58 (45.79%) - Winnings: ($90.00)
- Over/Under (this week): 8 - 4 (66.67%) - Winnings: $32.73
- Over/Under (season): 54 - 58 (48.21%) - Winnings: ($89.09)
- Total Weekly Winnings: $32.19
- Total Overall Winnings: ($242.88)
Check back later this week for week 9 picks.
Categories: Football
07-08 Week 8 NFL Picks
posted on 10/28/07 at 07:59:56 pm by Joel Ross
I just realized I never posted these. I had them done before today's games - honest! Anyway, here's the post I had written.
There's been a lot of talk lately about New England. They've yet to not cover. Reports are they are running up the score to prove to everyone that they can still win, even without cheating. They're doing a pretty good job of it - in last week's game, Brady was still in the game after they were up big - and they were still throwing the ball! How ironic would it be if Brady got injured in the second half of a blowout?
Of course, I'm not really complaining - having Randy Moss on my fantasy team changes that. If anyone cares, my team is 5-2, sitting at the top of my division. I claim no credit though. I was supposed to be at the live draft, but it turned out it was the day my son was born, so I ended up drafting based on the standard list. It didn't turn out too bad - Larry Johnson, Willis McGahee, Ronnie Brown, and Randy Moss were some of the names I ended up with. But I've had two running backs go down for the season - Brown and Carnell Williams. I was hurting, but I ended up trading to get Bryant Westrbrook, so hopefully I'll be OK for the rest of the season.
Anyway, on to my picks
- Indianapolis (-6) vs. Carolina (44.5 O/U): Indy has to win, so that next week, we can have a showdown between the Colts and the Patriots.
- Pittsburgh (-3) vs. Cincinnati (48 O/U)
- Oakland vs. Tennessee (-7) (40.5 O/U)
- New York Giants (-9.5) vs. Miami (48 O/U)
- Cleveland (-3) vs. St. Louis (45 O/U)
- Detroit vs. Chicago (-5) (45 O/U)
- Philadelphia (-1.5) vs. Minnesota (37.5 O/U)
- Houston* vs. San Diego (-11.5) (45 O/U): Apparently the oddsmakers are pretty sure the Chargers are back.
- Buffalo vs. New York Jets (-3) (37.5 O/U)
- Jacksonville vs. Tampa Bay (-3.5) (32 O/U)
- Washington vs. New England (-16.5) (48 O/U): Another 17 point spread for the Patriots. I wonder what it'll be next week against the Colts.
- New Orleans (-2.5) vs. San Francisco (40 O/U)
- Green Bay vs. Denver (-3) (42 O/U)
This week, I'm going with Indianapolis (-270), Tennessee (-300), Philadelphia (-130) and San Diego (-500) for my (not so) "lock solid" picks.
Check back next week to see how I did.
Categories: Football
How Well Does Live's New 411 Service Work?
posted on 10/25/07 at 09:09:42 pm by Joel Ross
I'm not really sure, but that's what I wondered this afternoon in my car. I needed to find the phone number to a business near my office so I could find out where they were located. There's a plethora of free 411 services out there right now. Google has one. There's Free-411, which was one of the first I remember, and Microsoft recently announced one.
Sitting in my car, those are the three that I could think of. I wanted to try a new service (I've used Free-411 in the past) so it was between Google and Microsoft. Since Microsoft technologies pay the bills around my house, I decided to go with that one.
Only I didn't know the number. I guessed it was 1-800-Live-411. So I called it.
Guess what? That's not the correct number. A nice young lady answered and said, "Hey sexy man, you're about to hear the best porn..." and then I hung up! I was pretty sure I had the wrong number! So I used my trusty stand by - Free-411.
Once I got home, I checked. It's 1-800-Call-411. Next time I'm out and need a number, I think I'll try that one instead!
Categories: Personal